




Java programátor expert

V dnešnom digitálnom svete sa dáta stali jednou z najcennejších komodít. Či už ide o sociálne siete, ktoré denne analyzujú miliardy interakcií medzi komunikujúcimi ľuďmi vo virtuálnom priestore internetu, o zdravotnícke systémy ukladajúce informácie o pacientoch a chorobách, ktorí prišli k lekárovi na vyšetrenie, alebo o digitálne obchodné inštrumenty ako Bitcoin, ktorý práve atakuje magickú úroveň sto tisíc dolárov za jeden Bitcoin.

V článku sa dozvieš:
Dáta sú všadeprítomné a stávajú sa hybnou silou inovácií vo všetkých oblastiach ľudskej činnosti. Ich efektívne využitie však vyžaduje porozumenie ich štruktúre a spracovaniu – čo nás privádza k dátovým štruktúram. Samotné dáta by nám boli zbytočné, ak by sme nepoznali spôsob, ako ich efektívne organizovať, uchovávať a spracovávať.
Predstavme si knižnicu bez akéhokoľvek systému usporiadania kníh – chaos, v ktorom je takmer nemožné nájsť, čo hľadáme. Podobne by svet počítačových systémov nedokázal zvládať súčasný objem dát, bez premyslených a optimalizovaných dátových štruktúr.
Tieto štruktúry, ktoré sú pre nás používateľov neviditeľnou architektúrou, sú zodpovedné za správnu kategorizáciu dát, uloženie a spracovanie takým spôsobom, aby napr. sekretárke pracujúcej s kancelárskym softvérom, hráčovi najnovšej počítačovej hry, zákazníkovi nakupujúci počas Black Friday v online obchode, či programátorovi dopytov vo veľkej databáze, priniesli takmer okamžite presne tie dáta, ktoré práve v danom okamihu potrebujú alebo očakávajú.
V tomto článku sa ponoríme do fascinujúceho sveta dátových štruktúr. Povieme si o tých základných, ako sú polia a zoznamy. Od tých základných, ako sú polia a zoznamy, až po pokročilé, ako hashovacie tabuľky alebo binárne stromy, ukážeme si, ako každá z nich hrá kľúčovú rolu v riešení rôznych výpočtových problémov. Dozvieš sa, prečo sú niektoré štruktúry ideálne na rýchle vyhľadávanie, iné na ukladanie veľkého množstva údajov a ďalšie na dynamickú správu dát.
Bez ohľadu na to, či si začínajúci programátor, zvedavý študent informatiky, ktorý chce lepšie pochopiť základy svojho budúceho remesla alebo už pracuješ v IT oblasti, tento článok ti poskytne praktický pohľad na dôležitosť správneho výberu dátových štruktúr.
Nepochopením kľúčových vlastností, silných a slabých stránok tej ktorej dátovej štruktúry a ich nevhodným, neefektívnym použitím strácame nielen drahocenný čas spracovania dát, ale aj plytváme hardvérovými prostriedkami. Ako všetci vieme, čas sú peniaze a napr. pomalá odozva pri vyhľadávaní tovaru na e-shope (tým chápeme spracovanie a vyfiltrovanie dát podľa zadaných kritérií používateľa) odradila od nákupu už nejedného zákazníka.
Dáta nie sú len bezvýznamne binárne čísla alebo text zložený z podivných ASCII znakov – sú základom nášho života. Svet moderných technológií poháňajú dáta, efektívne dátové štruktúry a algoritmy a tento článok ti niektoré z nich predstaví.
Dáta predstavujú základné stavebné kamene informácií. Sú to obyčajné fakty, čísla, texty, symboly, zvuky či obrazy, ktoré nemajú bez kontextu žiadny konkrétny význam. Môžeme si ich predstaviť ako jednotlivé dieliky puzzle – samostatne sú len malými časťami celku, no keď ich správne usporiadame, môžu vytvoriť krásny obrázok alebo stať sa pevným základom niečo väčšieho.
Dáta si vieme rozdeliť na základe štruktúrovanosti nasledovne:
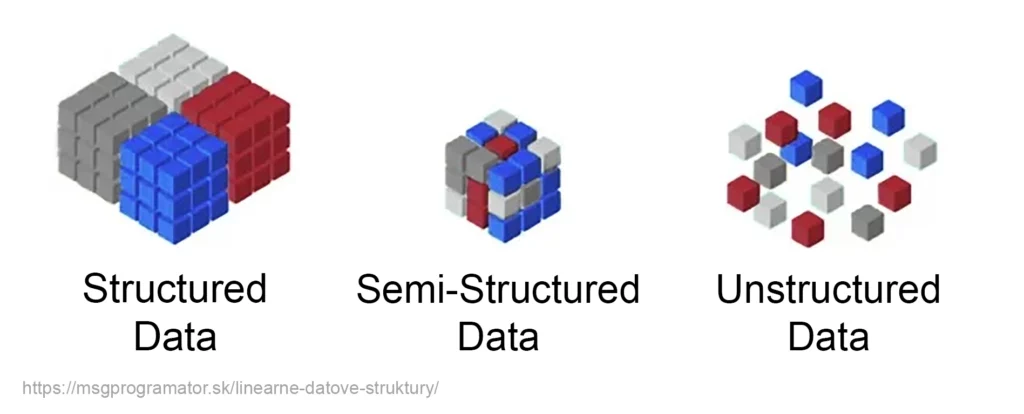
Dáta tvoria základ všetkých rozhodnutí v modernom svete. Firmy ich využívajú na analýzu trhu, vedci na výskum, lekári na diagnostiku a liečbu a vlády na plánovanie rozpočtov. Umelá inteligencia (AI) ako ju dnes poznáme by bez nich nikdy nevznikla. Vďaka technológiám, ktoré umožňujú zber, spracovanie a analýzu obrovského množstva dát, sme dnes schopní odhaľovať vzorce, robiť predpovede a pomocou štatistiky nachádzať nové znalosti, ktoré by inak zostali skryté.
Dátové štruktúry predstavujú spôsob organizácie, uchovávania a spracovania dát tak, aby sa dali efektívne používať v počítačových programoch. Poskytujú dátam určitú formu a určujú, ako budú dáta usporiadané, ale aj ako s nimi bude možné manipulovať. Sú základnými stavebnými kameňmi programu.
Vždy sa pri návrhu dátovej štruktúry, alebo pri výbere nejakej existujúcej snažíme optimalizovať rýchlosť operácií ako vyhľadávanie dát, ich načítanie a zápis. Sekundárne treba pamätať na to, že efektívne dátové štruktúry by mali minimalizovať pamäťovú náročnosť. To zahŕňa nielen priestor pre uloženie dát, ale aj pomocných štruktúr, indexov alebo metadát, ktoré pomáhajú pri rýchlejšom vyhľadávaní práve požadovaných informácií. Implementácia dátovej štruktúry by mala byť pre dané dáta, čo najjednoduchšia, aby sa eliminovalo riziko chýb. Rovnako podstatné je navrhnúť dátovú štruktúru tak, aby bola flexibilná a ľahko rozšíriteľná pre rôzne aplikácie.
Efektívny výber a implementácia údajových štruktúr má zásadný vplyv na zložitosť algoritmov, ktoré ich využívajú a teda celkový výkon aplikácie.
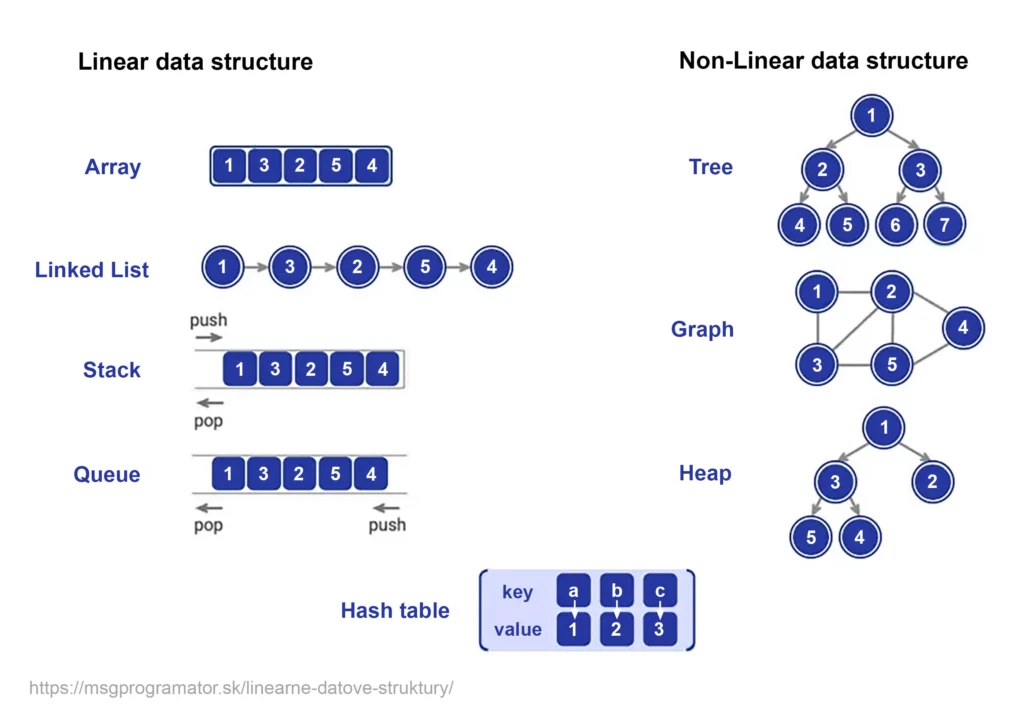
Dátové štruktúry môžeme rozdeliť podľa ich architektúry ukladania dát na:
Vyhľadávanie (search) – možno vyhľadať akýkoľvek prvok v dátovej štruktúre.
Vloženie (insert) – vkladanie nového prvku do dátovej štruktúry.
Aktualizácia (update) – nahradenie prvku iným prvkom v dátovej štruktúre.
Odstránenie (delete) – odstránenie existujúceho prvku z dátovej štruktúry.
Triedenie (sort) – prvky dátovej štruktúry možno triediť buď vzostupne alebo zostupne. V našich minulých článkoch sme sa vyčerpávajúco venovali triedeniu dát a triediacim algoritmom.
Dátová štruktúra sa niekedy nesprávne zamieňa za abstraktný dátový typ (ADT).
ADT hovorí, čo sa má urobiť, a dátová štruktúra hovorí, ako sa to má urobiť. Inými slovami, môžeme povedať, že ADT nám poskytuje návrh, zatiaľ čo dátová štruktúra poskytuje implementačnú časť. V konkrétnom ADT môžu byť implementované rôzne dátové štruktúry. Napr. ADT zásobník môže na dátovej úrovni využívať dátovú štruktúru pole, alebo pospájaný zoznam (linked list). Rozhodnutie, čo sa použije je na programátorovi a jeho špecifických požiadavkách.
Teraz si podrobne rozoberieme lineárne dátové štruktúry, ich základne vlastnosti, typy, výhody a nevýhody, ako aj najčastejšie prípady/príklady použitia.
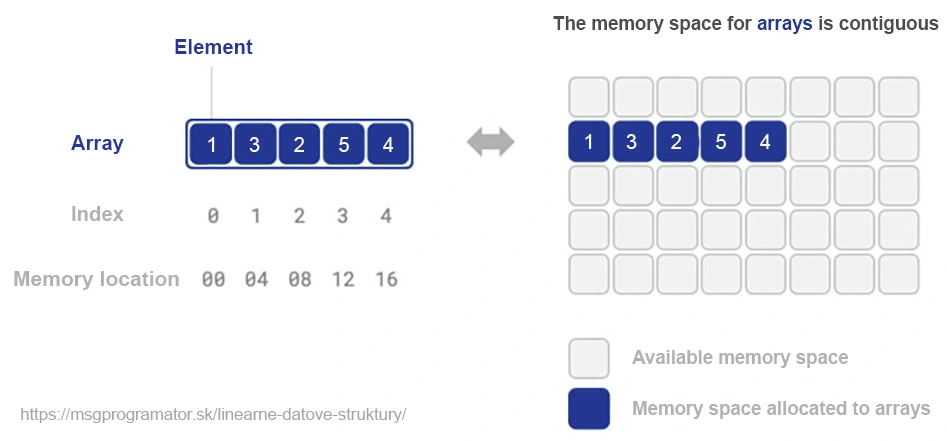
V programovaní sú polia jednou z najnákladnejších a najpoužívanejších dátových štruktúr. Ukladajú prvky v súvislom bloku pamäte, pričom každý prvok je prístupný pomocou číselného indexu. Zatiaľ čo polia ponúkajú prístupový čas O(1), čo je vynikajúce pre operácie náročné na čítanie, efektívnosť operácií zápisu (vkladanie a mazanie) sa môže výrazne líšiť v závislosti od umiestnenia operácie v poli a celkovej veľkosti poľa.
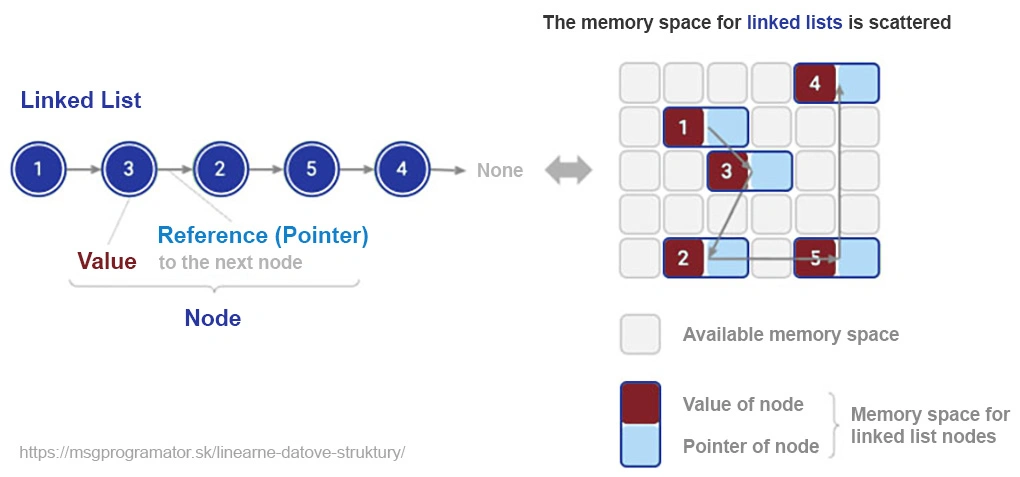
Spájaný zoznam je základná dátová štruktúra, ktorá sa odlišuje od poľa svojou dynamickou povahou a flexibilitou. Na rozdiel od polí, ktoré vyžadujú súvislý blok pamäte, zoznam pozostáva z uzlov rozptýlených v pamäti, pričom každý uzol obsahuje hodnotu a referenciu (ukazovateľ) na ďalší uzol. Táto vlastnosť umožňuje jednoduchú manipuláciu s prvkami, ale za cenu nižšej efektivity pri priamom prístupe.
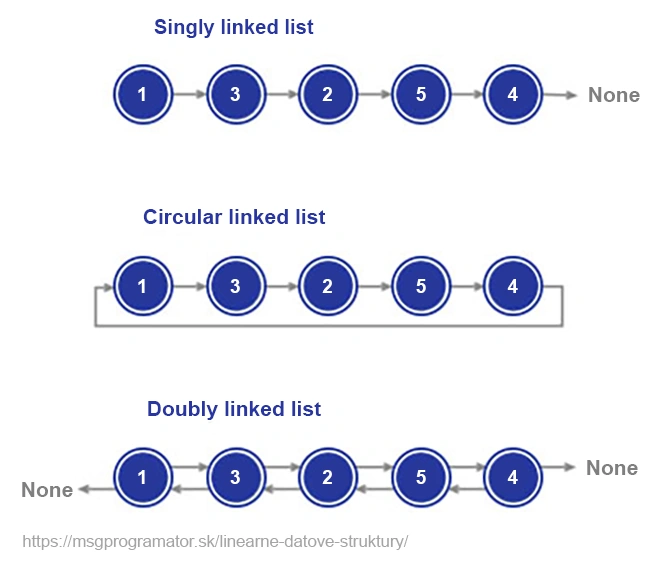
Predstav si správu histórie v prehliadači. Každý navštívený web je uložený ako uzol v zozname. Keď sa vrátiš späť na predchádzajúcu stránku, jednoducho sa pohneš na predchádzajúci uzol, čo je ideálny príklad, kde zoznam exceluje. Zoznamy sú nenahraditeľné pri úlohách vyžadujúcich flexibilitu a dynamické operácie s dátami, napriek tomu, že nie sú vhodné na všetky typy úloh.
Zásobník je jednou zo základných dátových štruktúr, ktorá funguje na princípe „posledný dovnútra, prvý von“ (LIFO – Last In, First Out). Predstavme si ho ako sadu tanierov uložených na sebe – nový tanier pridáme vždy navrch a pri odoberaní vždy siahneme po tom vrchnom. Táto jednoduchá, no mimoriadne užitočná štruktúra má široké využitie v oblasti programovania a informatiky.
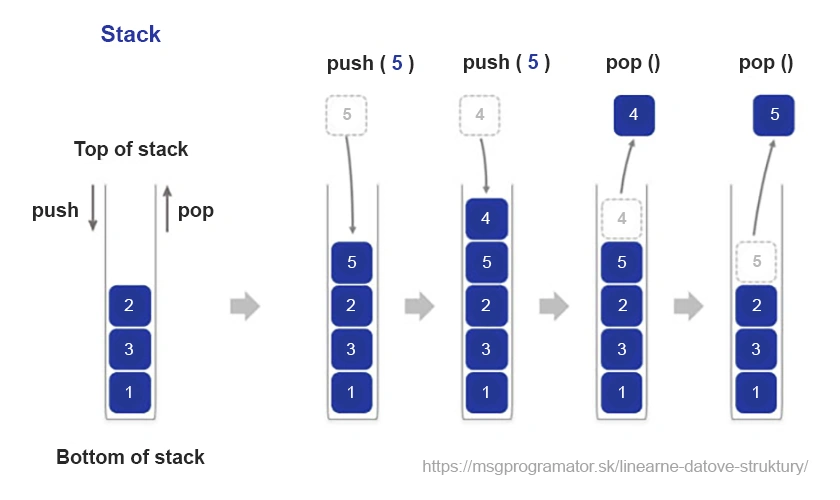
Predstavme si editor textu s funkciou naspäť. Každá zmena, ktorú vykonáme, sa pridá na zásobník. Keď klikneme na „späť“, posledná zmena sa odstráni a náš dokument sa vráti do predchádzajúceho stavu.
Zásobníky sú síce špecifické svojou jednoduchosťou a obmedzeniami, no práve vďaka týmto vlastnostiam sú nenahraditeľné v mnohých aplikáciách a algoritmoch, kde treba presne zachovať poradie vykonávania operácií. Pre viac informácií si prečítaj článok o zásobníku Java Stack.
Fronta je základná dátová štruktúra, ktorá funguje na princípe „prvý dovnútra, prvý von“ (FIFO – First In, First Out). Predstaviť si ju môžeme ako poradie objednávok čakajúcich na vybavenie – tá, ktorá prišla ako prvá bude aj ako prvá vybavená. Táto štruktúra je mimoriadne užitočná v situáciách, kde je dôležité zachovať poradie spracovania údajov.
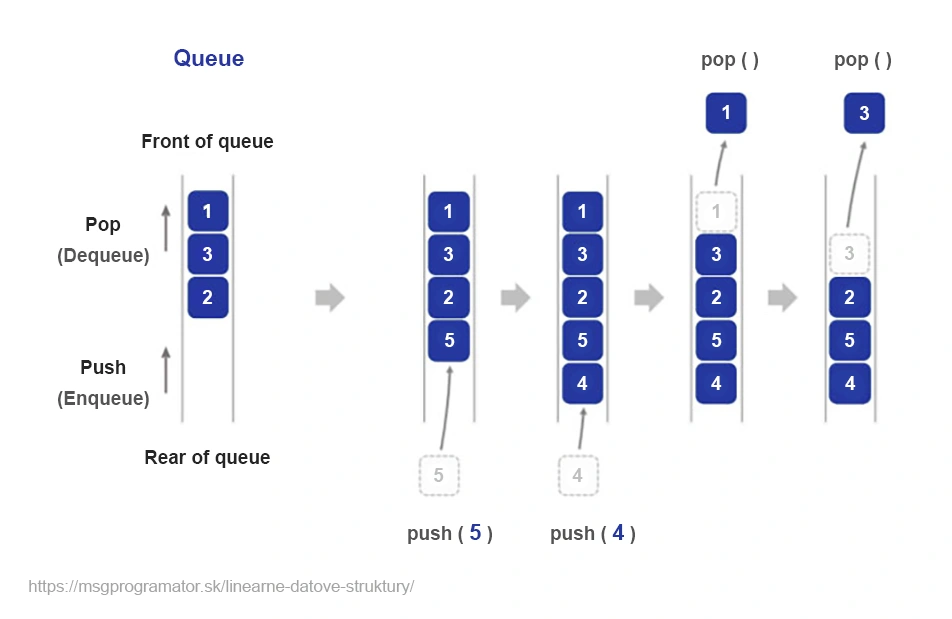
Predstavme si pokladňu v supermarkete. Každý zákazník, ktorý príde, sa zaradí na koniec radu (enqueue). Pokladník obslúži vždy zákazníka na začiatku radu (dequeue). Tento proces zachováva poradie príchodu zákazníkov.
Fronty sú užitočné všade tam, kde je potrebné efektívne spracovávať úlohy alebo údaje v poradí ich príchodu. Napriek obmedzeniam svojho sekvenčného prístupu sú jednou z najdôležitejších štruktúr v oblasti programovania.
Teraz si podrobne rozoberieme nelineárne dátové štruktúry, ich základne vlastnosti, typy, výhody a nevýhody, ako aj najčastejšie prípady/príklady použitia.
Strom je základná nelineárna dátová štruktúra, ktorá organizuje dáta hierarchicky. Skladá sa z uzlov, kde každý uzol má jeden nadradený uzol – rodiča (okrem koreňového uzla) a môže mať nula alebo viacero podriadených uzlov – potomkov. Táto štruktúra umožňuje efektívne spracovanie údajov, najmä pri hľadaní, triedení a reprezentácii vzťahov.
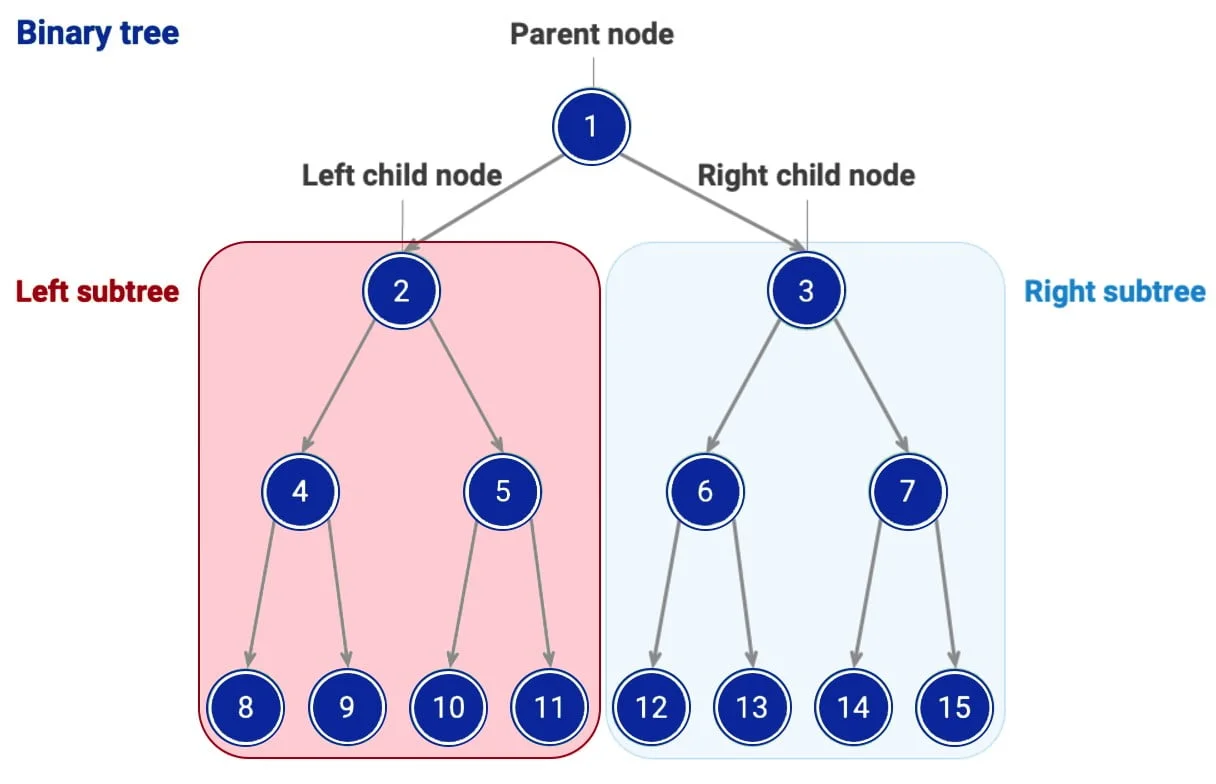
Hierarchická štruktúra: Stromy sú usporiadané do hierarchických vrstiev, pričom koreň je na vrchole a uzly pod ním reprezentujú ďalšie úrovne.
Uzly a hrany: Každý uzol obsahuje dáta a odkazy na svoje podriadené uzly. Hrany reprezentujú spojenia medzi uzlami.
Koreň (root): Je najvyšší uzol stromu, ktorý nemá rodičovský uzol.
Listy: Sú uzly, ktoré nemajú žiadnych potomkov (známe aj ako koncové uzly).
Výška stromu: Počet hrán na najdlhšej ceste od koreňa k listu.
Binárny strom: Každý uzol môže mať najviac dvoch potomkov – ľavý a pravý uzol.
Binárny vyhľadávací strom (BST): Binárny strom, kde ľavé podstromy obsahujú hodnoty menšie ako uzol a pravé podstromy hodnoty väčšie.
Vyvážené stromy: Stromy, ako AVL alebo červeno-čierne stromy, ktoré udržiavajú vyváženú výšku pre efektívnejšie operácie.
N-árny strom: Uzly môžu mať až N podriadených uzlov.
Trie: Špecializovaný strom na efektívne vyhľadávanie, napríklad pri práci so slovami alebo prefixmi.
Predstavte si rodokmeň – koreň stromu predstavuje najstaršieho predka a uzly nižšie znázorňujú jeho potomkov. Táto hierarchia je priamym príkladom využitia stromu na organizáciu a prehľadnú reprezentáciu údajov.
Stromy sú jednou z najdôležitejších dátových štruktúr v informatike. Ich schopnosť modelovať zložité vzťahy a efektívne manipulovať s hierarchickými dátami z nich robí neoddeliteľnú súčasť moderných algoritmov a aplikácií.
Graf je nelineárna dátová štruktúra, ktorá reprezentuje objekty (uzly, nazývané vrcholy) a vzťahy medzi nimi (nazývané hrany). Táto štruktúra je mimoriadne univerzálna a používa sa na modelovanie rôznych situácií, ako sú sociálne siete, dopravné mapy alebo vzťahy medzi entitami v databázach.
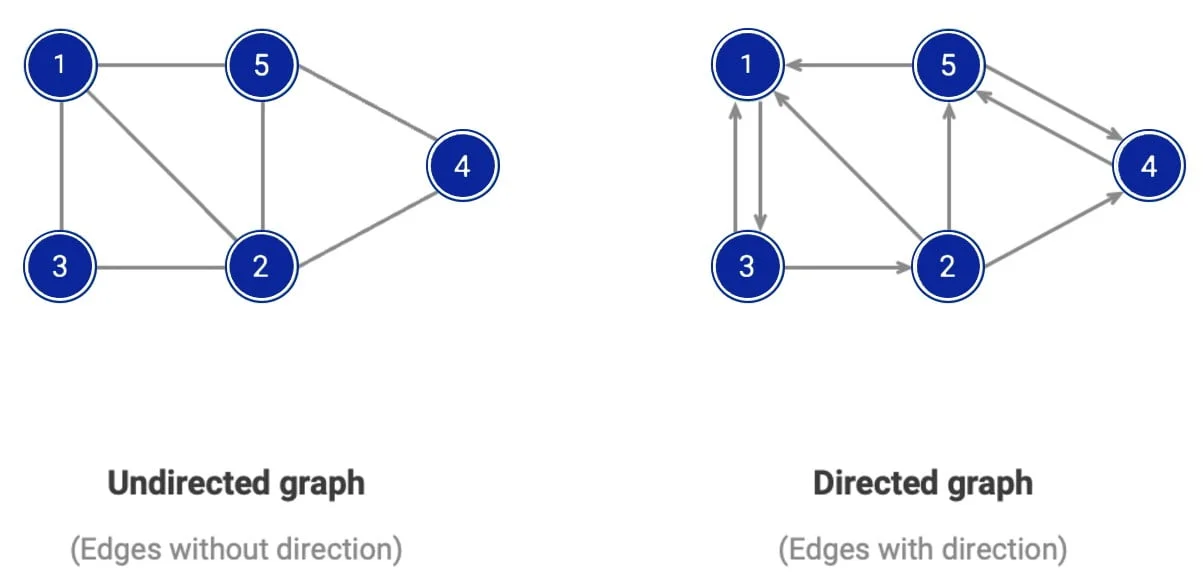
Vrcholy (Nodes): Základné časti grafu, ktoré reprezentujú objekty alebo entity.
Hrany (Edges): Spojenia medzi vrcholmi, ktoré reprezentujú vzťahy alebo interakcie.
Orientácia: Graf môže byť orientovaný (smerované hrany, napr. jednosmerná ulica) alebo neorientovaný (bez smerovania, napr. obojsmerná cesta).
Váha hrán: Niektoré grafy obsahujú váhy na hranách, ktoré reprezentujú hodnoty ako vzdialenosti, náklady alebo čas.
Neorientovaný graf (Undirected Graph): Hrany nemajú smer, spojenie medzi dvoma vrcholmi je vzájomné.
Orientovaný graf (Directed Graph alebo Digraph): Hrany majú smer a spájajú vrcholy v určitom poradí.
Vážený graf (Weighted Graph): Hrany majú pridelenú hodnotu (váhu).
Cyklový graf (Cyclic Graph): Obsahuje uzavreté cesty (cykly).
Acyklický graf (Acyclic Graph): Neobsahuje žiadne cykly.
Strom (Tree Graph alebo Tree): Špeciálny prípad acyklického grafu, kde je každý vrchol prístupný cez jednu cestu.
Súvislý graf (Connected Graph): Medzi každými dvoma vrcholmi existuje cesta.
Predstavme si mestskú dopravnú sieť. Každé miesto (zastávka) je vrchol a spojenie medzi zastávkami je hrana. Ak chceme nájsť najrýchlejšiu cestu medzi dvoma miestami, použijeme algoritmus, ktorý prechádza graf a identifikuje najkratšiu trasu.
Grafy sú nenahraditeľné pri riešení komplexných problémov, kde je kľúčové pochopiť a vedieť analyzovať vzťahy medzi objektmi. Vďaka svojej všestrannosti a bohatým možnostiam ich aplikovania sa stali základom mnohých oblastí modernej informatiky.
Teraz si podrobne rozoberieme tabuľkové dátové štruktúry, ich základne vlastnosti, typy, výhody a nevýhody, ako aj najčastejšie prípady/príklady použitia.
Hašovacia tabuľka je dátová štruktúra, ktorá implementuje asociatívne pole, v ktorom sa hodnoty (dáta) ukladajú a vyhľadávajú na základe unikátneho kľúča. Používa hašovaciu funkciu, ktorá prevádza kľúč na index v poli, čím umožňuje efektívne ukladanie a prístup k údajom.
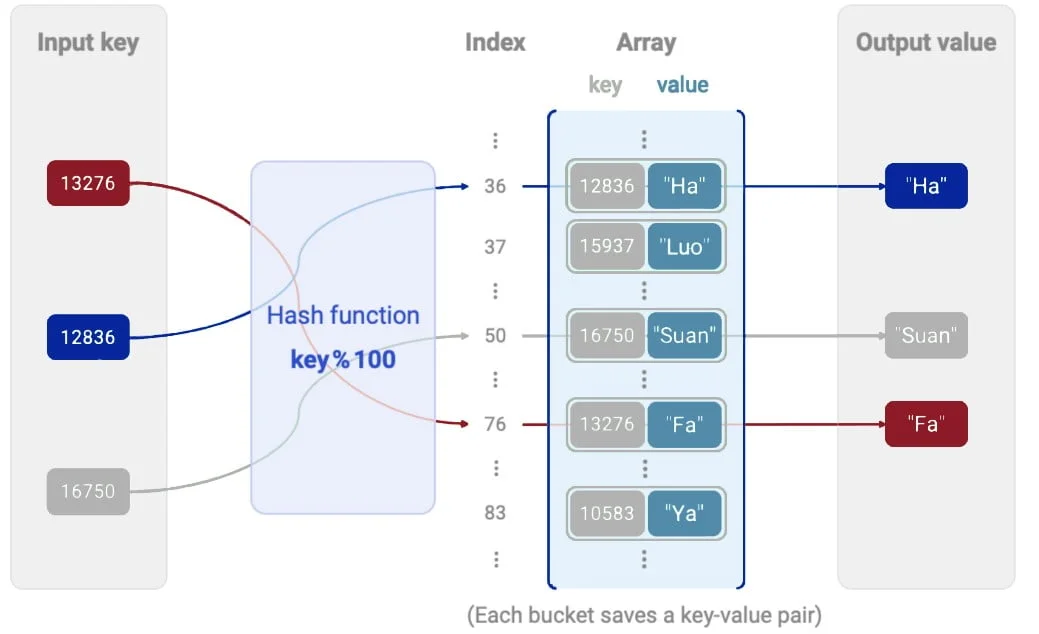
Hašovacia funkcia: Kľúč sa pomocou tejto funkcie prevádza na index v príslušnom poli. Kvalita hašovacej funkcie určuje výkon tabuľky.
Unikátne kľúče: Každý záznam v tabuľke je priradený unikátnemu kľúču.
Kolízie: Ak dva rôzne kľúče generujú rovnaký index, dochádza ku kolízii, ktorá sa rieši špecifickými technikami (napr. separátnym reťazením).
Separátne reťazenie: Každý index v tabuľke obsahuje zoznam alebo inú štruktúru, do ktorej sa ukladajú všetky hodnoty s rovnakým indexom.
Otvorené adresovanie: Ak nastane kolízia, hľadá sa iný voľný slot podľa určitého vzoru (napr. lineárne alebo kvadratické sondovanie).
Predstavme si telefónny zoznam, v ktorom chceme rýchlo vyhľadať číslo osoby na základe jej mena. Meno osoby slúži ako kľúč, ktorý sa pomocou hašovacej funkcie prevedie na index. Na tomto indexe je uložené príslušné telefónne číslo.
Hašovacie tabuľky sú výkonnou a efektívnou štruktúrou pre širokú škálu aplikácií, kde je prioritou rýchly prístup k údajom. Ich schopnosť efektívne spracovávať veľké množstvá dát ich robí nenahraditeľnými v celej oblasti IT.
Ešte by som rád stručne spomenul aspoň niektoré menej známe dátové štruktúry, s ktorými sa môžeme v IT stretnúť.
Binárny strom, ktorý spĺňa nasledovnú podmienku (každý rodičovský uzol je väčší alebo menší ako jeho potomkovia). Používa sa na implementáciu prioritných radov alebo v algoritme Heap Sort, ktorý sme si na našom blogu už predstavili.
Trie je stromová tabuľková štruktúra optimalizovaná na vyhľadávanie reťazcov, kde každý uzol reprezentuje časť kľúča. Používa sa v textových procesoroch, automatickom dopĺňaní alebo pri vyhľadávaní v databázach.
Slúži na reprezentáciu a spravovanie množín s disjunktnými prvkami. Používa sa pri grafových algoritmoch, ako je Kruskalov algoritmus.
Strom navrhnutý na efektívne riešenie problémov spojených s intervalmi a rozsahmi údajov. Je vhodný pre rýchle operácie na určenie sumy, minima alebo maxima v rozsahu.
Efektívna štruktúra na aktualizáciu a vyhľadávanie súčtov v postupnostiach. Používa sa v úlohách, ktoré počítajú rozsahy.
Špecializovaný strom na organizáciu bodov v K-rozmernom priestore. Využíva sa v algoritmoch pre spracovanie obrazu, počítačové videnie a databázové vyhľadávanie.
Reprezentuje všetky sufixy daného reťazca. Efektívny je najmä pri hľadaní podreťazcov a textových algoritmoch.
Maticové tabuľky sú dvojrozmerné alebo viacrozmerné polia, ktoré ukladajú dáta v riadkoch a stĺpcoch. Používa sa napr. v lineárnej algebre pre prácu s maticami.
Dvojrozmerná matica, kde riadky a stĺpce reprezentujú vrcholy grafu a hodnoty v matici indikujú existenciu hrán medzi vrcholmi. Používa sa na efektívne reprezentovanie hustých grafov a na rýchle zisťovanie existencie hrany medzi dvoma vrcholmi.
Zoznam, kde každý vrchol grafu obsahuje zoznam všetkých svojich susedných vrcholov. Ideálny na reprezentáciu riedkych grafov, pretože šetrí pamäť v porovnaní s maticou susednosti.
Štruktúra na ukladanie matíc s väčšinou nulových hodnôt, kde sa ukladajú iba nenulové hodnoty a ich polohy. Používa sa v oblastiach, ako je strojové učenie, analýza grafov a modelovanie veľkých riedkych dátových štruktúr.
Tabuľková štruktúra podobná hašovacej tabuľke, ktorá rieši kolízie alternatívnym spôsobom rozptyľovania kľúčov. Efektívna na spracovanie veľkého objemu dát s nižším rizikom zhlukovania pri kolíziách v hašovacích štruktúrach.
Dátové štruktúry sú neodmysliteľnou súčasťou programovania, pretože poskytujú spôsob ako efektívne organizovať, spracovať a manipulovať údaje. Lineárne dátové štruktúry (queue, stack, linked list, array) majú svoje špecifické výhody, nevýhody a oblasti použitia.
Ich správny výber a implementácia môže významne ovplyvniť výkon a efektivitu softvéru. Preto je pochopenie základných princípov dátových štruktúr kľúčové pre každého, kto sa chce hlbšie venovať programovaniu, algoritmom alebo databázam, aby tieto znalosti mohol využiť pri tvorbe optimalizovaných a inovatívnych riešení.
Ak hľadáš prácu a si Java programátor, prezri si naše benefity pre zamestnancov a reaguj na najnovšie ponuky práce.

Súvisiace články
