







Java programátor expert

Java Collections Framework tvorí absolútny základ práce s dátami v jazyku Java. Výber správnej dátovej štruktúry priamo ovplyvňuje pamäťovú náročnosť, rýchlosť spracovania aj čistotu kódu. Tento článok ti poskytne ucelený architektonický nadhľad nad celým ekosystémom kolekcií.

V článku sa dozvieš:
Tento text funguje ako centrálny dashboard celým ekosystémom kolekcií v Jave. Cieľom nie je detailne rozoberať vnútornú implementáciu každej triedy, na to slúžia samostatné špecializované články, na ktoré tu nájdeš priame prepojenia (hyperlinky). Pomôže ti pochopiť vzťahy medzi rozhraniami a poslúži ako praktická rozhodovacia matica pre tvoje každodenné programovanie.
Java Collections Framework (JCF) je unifikovaná architektúra určená na reprezentáciu a manipuláciu so skupinami objektov. Predstavuje softvérový ekosystém, ktorý štandardizuje spôsob, akým vývojári pracujú s dátovými štruktúrami. Pri spracovaní zoznamu používateľov, mapovaní unikátnych identifikátorov na objekty aj pri riadení poradia úloh vo fronte ti tento framework poskytuje hotové a vysoko optimalizované nástroje.
Pre plné porozumenie dôležitosti tohto frameworku sa musíme pozrieť na obdobie pred verziou JDK 1.2, ktorá bola vydaná v roku 1998. V raných verziách Javy neexistoval žiadny spoločný menovateľ pre správu dát. Vývojári mali k dispozícii iba pole, prípadne rané ad-hoc triedy ako Vector, Stack, Hashtable a Enumeration.
Tieto rané implementácie trpeli zásadnými nedostatkami:
Zmena nastala s príchodom JDK 1.2. Framework kolekcií navrhol a vyvinul predovšetkým Joshua Bloch a bol predstavený v Jave 2 v roku 1998. Ak poznáš jednu z najlepších kníh o Jave, Effective Java 3rd Edition, Joshua ti určite nie je neznámy. Hlavnou motiváciou bolo priniesť ľahko rozšíriteľný, adaptovateľný a vysoko výkonný framework, ktorý by obsahoval sadu základných kolekcií (dynamické polia, spájané zoznamy, stromové štruktúry, hashovacie tabuľky a podobne) a ich implementácia by bola efektívna a optimalizovaná primárne na výkon. Joshua Bloch navrhol čistú objektovo-orientovanú hierarchiu rozhraní a tried, ktoré oddelili abstrakciu od samotnej implementácie.
Pred týmto vydaním boli vývojári odkázaní na zoskupovanie objektov cez pole, triedy Vector a Hashtable, ktoré nebolo jednoduché rozšíriť a neimplementovali jednotné rozhranie. Programátori si tak väčšinovo programovali vlastné dátové štruktúry, alebo siahli po neštandardnej knižnici tretích strán.
Postupne JCF získaval nové funkcie. Revolučný skok priniesla verzia Java 5 v roku 2004. Uvedenie generických typov (Generics) navždy zmenilo prácu s kolekciami. Od tohto momentu mohol kompilátor kontrolovať typovú bezpečnosť už počas kompilácie.
Pozri sa na rozdiel v zápise pred verziou Java 5 a po nej:
// Starý spôsob zápisu pred verziou Java 5
List list = new ArrayList();
list.add("Java Collections Framework");
// Bolo nevyhnutné manuálne pretypovanie na konkrétny objekt
String result = (String) list.get(0);
// Moderný a bezpečný spôsob od verzie Java 5
List<String> modernList = new ArrayList<>();
modernList.add("Java Collections Framework");
// Žiadne pretypovanie nie je potrebné, kompilátor pozná typ prvkov
String modernResult = modernList.get(0);
Evolúcia pokračovala vo verzii Java 8, ktorá integrovala Java Stream API a funkcionálne rozhrania, čím umožnila deklaratívne spracovanie dát priamo nad existujúcimi kolekciami. Najnovším míľnikom je Java 21, ktorá zavádza SequencedCollections a definuje jednotné rozhranie pre prácu s kolekciami, ktoré si udržiavajú pevne stanovené poradie prvkov.
Používanie robustného a štandardizovaného ekosystému prináša do vývoja aplikácií štyri hlavné benefity:
Architektúra Java Collection Framework stojí na troch základných pilieroch, ktoré spolu tvoria koherentný systém pre správu dát. Sú to rozhrania, konkrétne implementácie a algoritmy. Tento prístup striktne oddeľuje to, čo chceme s dátami robiť, od toho, ako sa to reálne na pozadí vykoná.
Keď pochopíš tento hierarchický strom, dokážeš písať kód, ktorý je modulárny a pripravený na zmeny bez nutnosti prepisovania biznis logiky.
Rozhrania tvoria kostru celého frameworku. Definujú sadu metód ako záväzok, ktoré musí každá trieda implementujúca dané rozhranie bezpodmienečne poskytnúť. Rozhrania v Java Collections Framework neurčujú, ako sa dáta ukladajú do pamäte, ani akú časovú zložitosť budú mať jednotlivé operácie. Definujú iba správanie dátovej štruktúry.
Vďaka tomuto prístupu sa v praxi uplatňuje kľúčové pravidlo objektovo-orientovaného dizajnu: programuj s využitím rozhraní, netrvaj na konkrétnej implementácii.
Pozri sa na praktický príklad, prečo je tento prístup výhodný:
// Správny prístup: premenná je typu rozhrania
List<String> developerNames = new ArrayList<>();
developerNames.add("Jozef");
// Ak neskôr potrebuješ zmeniť implementáciu, zmeníš iba inicializáciu.
// Zvyšok kódu, ktorý pracuje s premennou developerNames, zostáva bez zmeny.
developerNames = new LinkedList<>();
Keď si hneď na začiatku definuješ ako ArrayList<String> developerNames, uzamkneš si svoj kód pre jeden konkrétny typ a stratíš možnosť flexibilnej úpravy v budúcnosti.
Konkrétne triedy sú reálne, hmatateľné implementácie spomínaných rozhraní. Sú to dátové štruktúry, ktoré už priamo definujú spôsob uloženia dát v operačnej pamäti a reálnu logiku jednotlivých operácií.
JCF ti ponúka viacero implementácií pre jedno rozhranie z veľmi racionálneho dôvodu. Neexistuje jedna dokonalá dátová štruktúra, ktorá by bola najlepšia vo všetkých scenároch. Každá implementácia prináša určité kompromisy.
Napríklad pri rozhraní List máš k dispozícii:
Voľbou konkrétnej triedy teda priamo ovplyvňuješ efektivitu svojej aplikácie v závislosti od toho, aké operácie s dátami vykonávaš najčastejšie.
Tretím pilierom frameworku sú algoritmy, ktoré poskytujú opakovane použiteľnú funkcionalitu pre prácu s kolekciami. Ide o polymorfné metódy, čo znamená, že rovnaká metóda dokáže pracovať s rôznymi implementáciami daného rozhrania.
Tieto algoritmy sú sústredené predovšetkým v pomocných utility triedach Collections a Arrays. Namiesto manuálnej implementácie zložitých triediacich alebo vyhľadávacích algoritmov ti framework dáva k dispozícii hotové riešenia, ktoré sú vysoko optimalizované (napríklad implementácia algoritmu Timsort pre triedenie).
Medzi základné operácie, ktoré tieto utility triedy poskytujú, patria:
List<Integer> scores = new ArrayList<>();
scores.add(82);
scores.add(91);
scores.add(73);
// Polymorfný algoritmus na zoradenie zoznamu
Collections.sort(scores);
// Algoritmus na náhodné premiešanie prvkov
Collections.shuffle(scores);
Vďaka integrácii algoritmov priamo do frameworku je zabezpečené, že bežné operácie nad dátami nemusíš písať ručne, čím sa minimalizuje riziko vzniku chýb v zdrojovom kóde.
Pre prehľadnosť celej štruktúry pomôže vizualizácia hierarchie. Diagram zobrazuje, ako sa rozhrania a konkrétne implementácie zoraďujú v rámci frameworku:
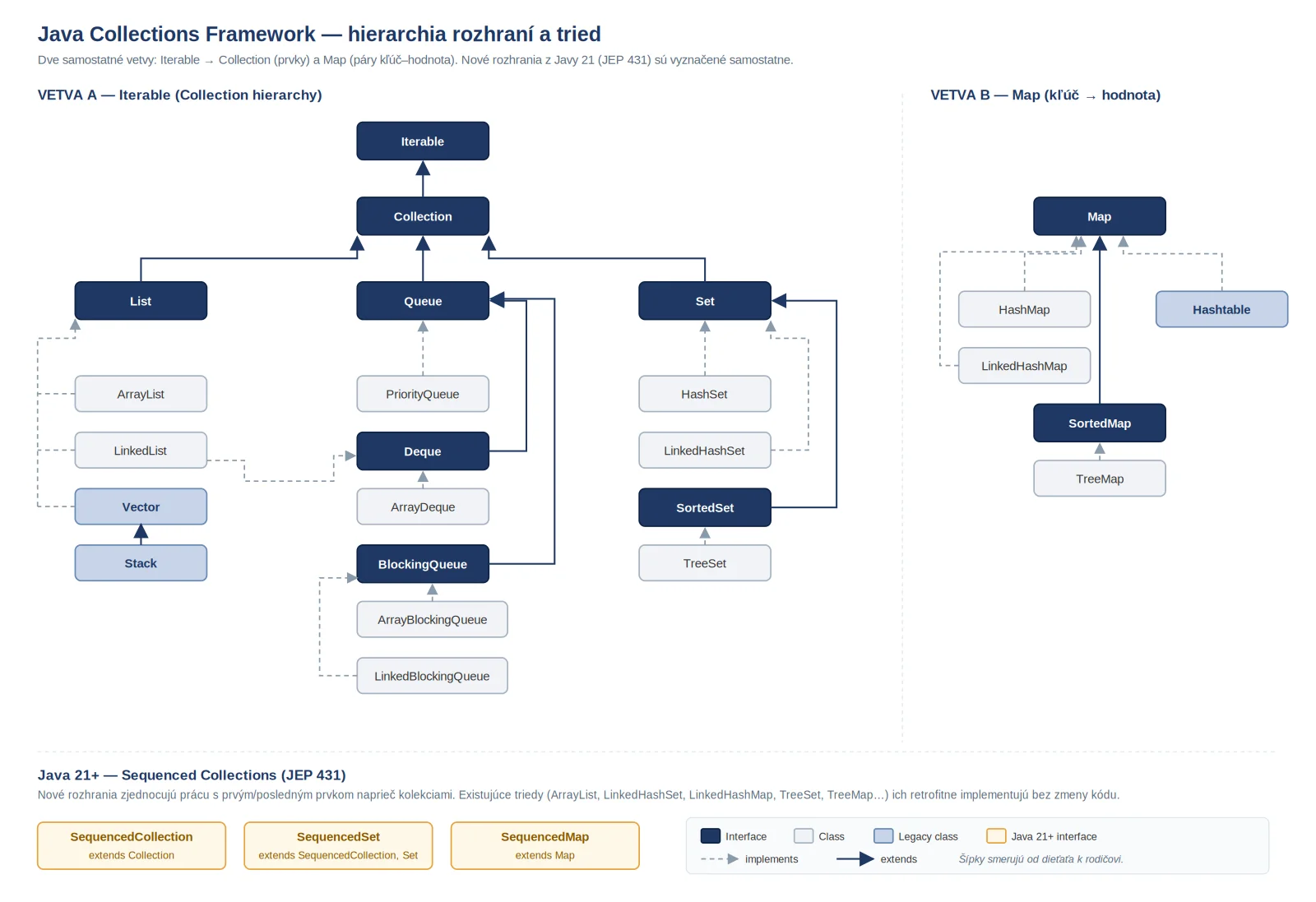
Ak chceš dokonale ovládať Java Collections Framework, musíš najskôr porozumieť hlavnej myšlienke návrhu JCF. Celá hierarchia je navrhnutá tak, aby maximalizovala znovupoužiteľnosť kódu. Na vrchole tohto rebríčka nestojí samotné rozhranie Collection, ale rozhranie Iterable, ktoré zabezpečuje jednotný spôsob prechádzania prvkov.
Medzi najdôležitejšie rozhrania JCF, ktoré poskytujú všeobecnú štruktúru pre prácu s rôznymi typmi kolekcií, patria Iterable, Collection, List, Queue, Set a Map.
Rozhranie Iterable predstavuje absolútny vrchol hierarchie pre drvivú väčšinu kolekcií (s výnimkou rozhrania Map). Ak trieda implementuje toto rozhranie, dáva tým kompilátoru najavo, že jej prvky je možné sekvenčne prechádzať jedného po druhom.
Hlavnou úlohou rozhrania Iterable je poskytnúť metódu iterator(), ktorá vracia objekt implementujúci rozhranie Iterator. Práve tento objekt nesie reálnu logiku a stav prechádzania štruktúry.
Rozhranie Iterator definuje tri kľúčové metódy, ktoré umožňujú bezpečnú manipuláciu s prvkami počas cyklu:
| Metóda | Návratový typ | Popis funkcie |
|---|---|---|
| hasNext() | boolean | Vracia true, ak kolekcia obsahuje ďalšie prvky na prechádzanie. |
| next() | E | Vracia nasledujúci prvok v poradí a posúva ukazovateľ vpred. |
| remove() | void | Odstráni z kolekcie posledný prvok vrátený týmto iterátorom. |
Prítomnosť rozhrania Iterable je zároveň podmienkou na to, aby si nad danou kolekciou mohol/-la použiť skrátený for-each cyklus, ktorý bol predstavený v Jave 5. Kompilátor na pozadí tento for-each cyklus automaticky transformuje na klasické volanie iterátora.
Pozri sa na praktické porovnanie oboch prístupov. Uvidíš, prečo je explicitné použitie iterátora nevyhnutné, ak chceš prvky počas prechádzania bezpečne mazať:
List<String> frameworkComponents = new ArrayList<>();
frameworkComponents.add("List");
frameworkComponents.add("Set");
frameworkComponents.add("Map");
// 1. Prístup pomocou for-each cyklu (čítanie dát)
for (String component : frameworkComponents) {
System.out.println(component);
// Pozor: frameworkComponents.remove(component) tu vyvolá
// ConcurrentModificationException
}
// 2. Prístup pomocou explicitného Iteratora (bezpečné mazanie dát)
Iterator<String> iterator = frameworkComponents.iterator();
while (iterator.hasNext()) {
String component = iterator.next();
if (component.equals("Map")) {
// Bezpečné odstránenie prvku priamo cez iterátor
iterator.remove();
}
}
Rozhranie Collection rozširuje rozhranie Iterable a definuje základný kontrakt pre prácu so skupinami objektov. Toto rozhranie priamo neimplementujú žiadne konkrétne triedy v Jave, pretože je príliš abstraktné. Namiesto toho slúži ako spoločný základ pre špecifickejšie sub-rozhrania: List, Set a Queue.
Definuje základné operácie, ktoré očakávaš od každej dátovej štruktúry, teda pridávanie, mazanie, kontrolu veľkosti a transformáciu na pole.
Prehľad najdôležitejších metód rozhrania Collection:
| Metóda | Návratový typ | Popis funkcie |
|---|---|---|
| add(E e) | boolean | Zabezpečí, že kolekcia bude obsahovať špecifikovaný prvok. |
| remove(Object o) | boolean | Odstráni jeden konkrétny prvok z kolekcie, ak sa v nej nachádza. |
| contains(Object o) | boolean | Vracia true, ak kolekcia obsahuje aspoň jeden hľadaný prvok. |
| size() | int | Vracia aktuálny počet prvkov uložených v danej kolekcii. |
| isEmpty() | boolean | Rýchla kontrola, či je veľkosť kolekcie rovná nule. |
| clear() | void | Úplne vyprázdni kolekciu a odstráni všetky referencie na objekty. |
| toArray() | Object[] | Transformuje celú kolekciu na klasické pole objektov. |
Tento dashboard ti poslúži ako hlavný rozcestník pre všetky dôležité dátové štruktúry v Jave. Každá sekcia ti poskytne rýchly kontext, kľúčové vlastnosti a predovšetkým odkaz na detailný článok, kde rozoberáme vnútorné fungovanie danej triedy do posledného detailu.
Rozhranie List reprezentuje usporiadanú sekvenciu prvkov, v ktorej záleží na presnom poradí vloženia. Na rozdiel od rozhrania Set umožňuje ukladanie duplicitných hodnôt a poskytuje presnú kontrolu nad tým, kde v zozname bude prvok umiestnený pomocou celočíselného indexu.
ArrayList je absolútne najpoužívanejšia kolekcia v Jave. Interne využíva dynamické pole. Vyniká v operáciách čítania, kedy vďaka indexácii dosahuje časovú zložitosť O(1). Jej slabinou je vkladanie prvkov do stredu zoznamu alebo zmena veľkosti poľa pri naplnení kapacity, kedy musí alokovať nové pole a dáta skopírovať.
LinkedList je implementácia založená na obojsmerne prepojených uzloch. Každý prvok pozná referenciu na svojho predchodcu aj nasledovníka. Je ideálnou voľbou, ak aplikácia vyžaduje neustále pridávanie a mazanie prvkov zo začiatku alebo konca zoznamu v čase O(1). Naopak, náhodný prístup k prvkom cez index vyžaduje sekvenčné prechádzanie celej štruktúry, čo degraduje výkon na časovú zložitosť O(n).
Vector patrí medzi historické komponenty z čias JDK 1.0. Funguje na rovnakom princípe ako ArrayList, no s tým rozdielom, že všetky jej metódy sú synchronizované. V moderných jednovláknových aplikáciách spôsobuje zbytočnú výkonnostnú réžiu, preto ju v novom kóde nepoužívaj.
Stack predstavuje klasickú dátovú štruktúru typu LIFO (Last In, First Out). Z architektonického hľadiska bol jej návrh v Jave chybou, pretože rozširuje triedu Vector, čím zdedil indexový prístup a nevhodnú synchronizáciu. Ak potrebuješ zásobník, moderná Java odporúča použiť rozhranie Deque.
Rozhranie Set modeluje matematickú abstrakciu množiny. Jeho hlavnou vlastnosťou je, že nesmie obsahovať duplicitné prvky. Ak sa pokúsiš vložiť prvok, ktorý sa už v množine nachádza, operácia vráti hodnotu false a štruktúru nezmení.
HashSet je najefektívnejšia a najpoužívanejšia implementácia množiny. Interne využíva inštanciu HashMap, kde ukladá prvky ako kľúče. Ponúka konštantnú časovú zložitosť O(1) pre základné operácie, no nezaručuje absolútne žiadne poradie prvkov pri iterácii.
LinkedHashSet rozširuje HashSet, ale navyše interne udržiava obojsmerne prepojený zoznam prechádzajúci všetkými prvkami. Vďaka tomu zaručuje, že prvky budú iterované presne v takom poradí, v akom boli do množiny vložené. Daňou za zachovanie poradia je mierne vyššia pamäťová náročnosť.
TreeSet na rozdiel od predchádzajúcich dvoch implementácií interne stavia na štruktúre červeno-čierneho stromu prostredníctvom TreeMap. Všetky prvky sú neustále automaticky usporiadané podľa ich prirodzeného poradia alebo podľa explicitne definovaného komparátora. Vyhľadávanie, pridávanie a mazanie prebieha v logaritmickom čase O(log n).
Tieto rozhrania sú navrhnuté na uchovávanie prvkov pred ich následným spracovaním. Štandardná fronta funguje na princípe FIFO (First In, First Out), zatiaľ čo Deque umožňuje manipuláciu s prvkami z oboch koncov štruktúry.
PriorityQueue je fronta, ktorá nespracováva prvky na základe času ich príchodu, ale na základe ich priority. Prvky sú organizované pomocou dátovej štruktúry halda (heap). Prvok s najvyššou prioritou je vždy na čele fronty pripravený na odber.
ArrayDeque je moderná a vysoko efektívna implementácia obojstrannej fronty postavená na kruhovom poli. Ak potrebuješ implementovať zásobník (Stack) alebo štandardnú frontu (Queue) v jednovláknovom prostredí, ArrayDeque prekonáva v rýchlosti aj v pamäťovej efektivite LinkedList aj Stack.
BlockingQueue je špecializované rozhranie patriace do balíka java.util.concurrent. Je kľúčovým komponentom pre budovanie asynchrónnych systémov a architektúry producent-konzument. Ak je fronta prázdna, operácia odberu vlákno zablokuje, kým sa neobjavia nové dáta. Ak je fronta plná, zablokuje sa vlákno, ktoré sa snaží dáta vložiť.
Hoci Map nepatrí priamo pod rozhranie Collection, je integrálnou súčasťou JCF. Reprezentuje štruktúru, ktorá mapuje unikátne kľúče na konkrétne hodnoty. Každý kľúč môže byť v mape prítomný iba raz.
HashMap je absolútny štandard pre prácu s dvojicami kľúč-hodnota. Využíva hashovaciu funkciu na distribúciu kľúčov do takzvaných bucketov. Poskytuje vynikajúci výkon s časovou zložitosťou O(1) pre zápis aj čítanie. Poradie kľúčov sa pri zmene veľkosti mapy môže kedykoľvek zmeniť.
LinkedHashMap kombinuje vlastnosti hashovacej tabuľky a prepojeného zoznamu. Zachováva presné poradie vkladania kľúčov, čo je ideálne napríklad pri implementácii LRU (Least Recently Used) cache pamätí. Výkonnostne je takmer identická s HashMap.
TreeMap je implementácia rozhrania NavigableMap, ktorá garantuje usporiadanie kľúčov. Podobne ako TreeSet využíva na pozadí vyvážený červeno-čierny strom. Ponúka operácie pre hľadanie najbližšieho vyššieho alebo nižšieho kľúča s časovou zložitosťou O(log n).
Hashtable je legacy synchrónna mapa z raných verzií Javy. Nepovoľuje vkladanie null hodnôt ani null kľúčov. Kvôli globálnemu zamykaniu metód je v modernom vývoji nahradená optimalizovanou triedou ConcurrentHashMap.
Verzia Java 21 priniesla zásadné upratovanie v hierarchii frameworku zavedením rozhraní, ktoré unifikujú prácu s kolekciami s vopred definovaným poradím (encounter order). Pred týmto updatom neexistoval spoločný spôsob, ako získať prvý alebo posledný prvok z ArrayList, LinkedHashSet a TreeMap jednotným volaním.
…SequencedCollections (JEP 431) priniesla v Jave 21 prvé spoločné rozhranie pre kolekcie s pevným poradím prvkov, takže metódy getFirst() a getLast()konečne fungujú pri ArrayList, LinkedHashSet aj TreeMap jednotne?
SequencedCollection, SequencedSet a SequencedMap sú nové rozhrania pridávajú do typovej hierarchie jednotné metódy, ktoré odstraňujú potrebu používania neintuitívnych konštrukcií (napríklad získavanie posledného prvku cez indexovanie veľkosti zmenšenej o jedna):
// Príklad unifikovaného prístupu v Java 21
SequencedCollection<String> sequencedList = new ArrayList<>();
sequencedList.add("Prvý");
sequencedList.add("Druhý");
// Jednotné a bezpečné metódy naprieč celou hierarchiou
String first = sequencedList.getFirst();
String last = sequencedList.getLast();
// Otočenie celej kolekcie v čase O(1) bez kopírovania dát
SequencedCollection<String> reversedView = sequencedList.reversed();
Správny výber kolekcie závisí od dvoch hlavných faktorov: od operácií, ktoré bude tvoja aplikácia vykonávať najčastejšie a od povahy samotných dát (či vyžaduješ unikátnosť, usporiadanie alebo prístup cez kľúč). Ak zvolíš nesprávnu implementáciu, riskuješ zbytočnú degradáciu výkonu pri raste objemu dát.
Pre rýchlu orientáciu a optimalizáciu výkonu využi túto porovnávaciu maticu. Časová zložitosť je uvedená pre priemerný prípad (average case) pomocou Big O notation:
| Trieda | Add | Delete | Search | Prístup cez index | Poradie prvkov | Povolené null |
|---|---|---|---|---|---|---|
| ArrayList | O(1) | O(n) | O(n) | O(1) | podľa vloženia | áno |
| LinkedList | O(1) | O(1) | O(n) | O(n) | podľa vloženia | áno |
| HashSet | O(1) | O(1) | O(1) | N/A | žiadne | áno |
| LinkedHashSet | O(1) | O(1) | O(1) | N/A | podľa vloženia | áno |
| TreeSet | O(log n) | O(log n) | O(log n) | N/A | usporiadané | nie |
| HashMap | O(1) | O(1) | O(1) | N/A | žiadne | kľúč aj hodnota |
| TreeMap | O(log n) | O(log n) | O(log n) | N/A | podľa kľúča | iba hodnota |
| ArrayDeque | O(1) | O(1) | O(n) | N/A | podľa vloženia | nie |
| PriorityQueue | O(log n) | O(log n) | O(n) | N/A | podľa priority | nie |
Poznámka: Pre ArrayList je pridanie na koniec v priemere O(1), ale v prípade potreby zväčšenia kapacity poľa dochádza k jednorazovej operácii so zložitosťou O(n).
Aby nebolo potrebné pamätať si časovú zložitosť pre jednotlivé kolekcie, pomôžu reálne scenáre, kedy jednotlivé štruktúry nasadiť.
Vývojári často robia chybu a automaticky volia LinkedList, ak očakávajú pri vkladaní veľa dát. V reálnom svete však ArrayList takmer vždy vyhráva.
Rýchlosť algoritmov nie je jediným kritériom, na ktoré musíme myslieť. Druhou stranou mince je pamäťová náročnosť jednotlivých objektov v operačnej pamäti.
Kolekcie založené na uzloch, ako napríklad LinkedList, nesú masívny pamäťový overhead. Pre každý jeden vložený prvok musí LinkedList vytvoriť interný objekt Node. Tento objekt obsahuje tri referencie: na samotné dáta, na predchádzajúci uzol a na nasledujúci uzol. V 64-bitovej architektúre s JVM môže samotná réžia týchto referencií niekoľkonásobne prevýšiť veľkosť reálne ukladaných dát.
Podobne je na tom HashMap. Interne alokuje pole bucketov a pri každom zápise vytvára objekty typu Node, ktoré okrem kľúča a hodnoty držia aj vypočítaný hash a referenciu na ďalší uzol v prípade kolízie.
Ak vyvíjaš aplikáciu s obmedzenými pamäťovými zdrojmi alebo spracovávaš milióny záznamov, drž sa týchto zásad:
Keď presunieš prácu s kolekciami do viacvláknového prostredia (multithreading), charakteristické vlastnosti štandardných tried sa dramaticky zmenia. Väčšina základných implementácií, ako sú ArrayList, HashSet alebo HashMap, nie je bezpečná pre prácu vo viacvláknovom prostredí. Ak viacero vlákien súčasne modifikuje takúto kolekciu, dôjde k nepredvídateľnému správaniu, korupcii dát alebo zlyhaniu aplikácie.
Na zabezpečenie bezpečnosti vlákien poskytuje Java tri základné architektonické prístupy. Pochopenie rozdielov medzi nimi je kľúčové pre zachovanie vysokej priepustnosti aplikácie.
Tieto triedy dosahujú bezpečnosť vlákien tak, že každá jedna ich metóda obsahuje kľúčové slovo synchronized. To znamená, že pri akomkoľvek volaní metódy dôjde k uzamknutiu celého objektu kolekcie na úrovni monitora. Ak jedno vlákno iba číta prvok, žiadne iné vlákno nemôže do kolekcie zapisovať ani z nej čítať. Tento prístup vytvára obrovské úzke hrdlo (bottleneck) a degraduje výkon.
Pomocou utility metód triedy Collections môžeš premeniť akúkoľvek štandardnú kolekciu na synchronizovanú. Fungujú ako obal (wrapper), ktorý interne zachytáva volania a zapisuje ich do synchronizovaných blokov. Z hľadiska výkonu trpia rovnakým problémom ako legacy triedy, teda uzamykajú celý objekt pre každú operáciu.
Vo väčšine moderných aplikácií predstavujú najefektívnejšie riešenie. Namiesto zamykania celého objektu využívajú sofistikované algoritmy, ako je segmentové uzamykanie (lock striping) alebo mechanizmus porovnaj a vymeň (Compare-And-Swap/CAS operácie).
Príkladom je ConcurrentHashMap, ktorá uzamyká iba konkrétny bucket (časť poľa), v ktorej prebieha zápis, zatiaľ čo operácie čítania prebiehajú úplne bez uzamykania. Ďalším príkladom je CopyOnWriteArrayList, ktorý pri každej modifikácii vytvorí kompletnú novú kópiu poľa, čo je ideálne pre scenáre, kde čítanie dát vysoko prevažuje nad ich zápisom.
Pri prechádzaní kolekcií pomocou iterátorov vo viacvláknovom (alebo aj nevhodne navrhnutom jednovláknovom) prostredí narazíš na dva odlišné typy správania: fail-fast a fail-safe (v modernej terminológii označované ako weakly consistent).
Tieto iterátory operujú priamo nad pôvodnými dátami kolekcie. Počas prechádzania neustále kontrolujú interné počítadlo modifikácií kolekcie s názvom modCount. Ak zistia, že kolekcia bola štrukturálne zmenená (prvok bol pridaný alebo zmazaný mimo samotného iterátora), okamžite vyvolajú výnimku ConcurrentModificationException.
Všetky štandardné kolekcie z balíka java.util (ArrayList, HashMap, HashSet) vracajú fail-fast iterátory. Ich cieľom je radšej okamžite zlyhať, než pokračovať v behu s nekonzistentnými dátami.
Tieto iterátory nevyvolávajú výnimku pri zmene štruktúry počas iterácie. Buď pracujú nad klonom (kópiou) pôvodných dát, ktorý bol vytvorený v momente inicializácie iterátora (ako CopyOnWriteArrayList), alebo zvládajú zmeny za behu vďaka špecifickému návrhu dátovej štruktúry (ako ConcurrentHashMap). Zmeny vykonané v kolekcii počas iterácie sa môžu, ale nemusia zobraziť v priebehu cyklu.
| Vlastnosť | Fail-Fast iterátor | Fail-Safe (weakly consistent) iterátor |
|---|---|---|
| Vyvolanie výnimky | Áno (ConcurrentModificationException). | Nie, nikdy nevyvolá túto výnimku. |
| Práca nad kópiou | Nie, pracuje nad reálnymi dátami. | Áno, prípadne nad špecifickým pohľadom pamäte. |
| Pamäťový overhead | Minimálny, iba kontrola počítadla. | Vyšší (pri CopyOnWrite štruktúrach). |
| Príklady tried | ArrayList, HashSet, HashMap | ConcurrentHashMap, CopyOnWriteArrayList |
Pozri sa na praktický príklad správania ConcurrentHashMap vo viacvláknovom prostredí:
// Inicializácia bezpečnej konkurenčnej mapy
Map<String, Integer> stock = new ConcurrentHashMap<>();
stock.put("Java", 100);
stock.put("Kotlin", 50);
Iterator<String> keyIterator = stock.keySet().iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
// Fail-safe iterátor toto zvládne bez vyvolania výnimky
stock.put("Scala", 30);
} Efektívna práca s Java Collections Framework zahŕňa aj znalosť nástrojov, ktoré umožňujú dáta transformovať, filtrovať a hromadne spracovávať bez nutnosti písania manuálnych cyklov a pomocných podmienok.
Trieda java.util.Collections obsahuje výhradne statické metódy, ktoré pracujú s kolekciami alebo ich vracajú. Ide o silný nástroj na vykonávanie bežných operácií.
Medzi najdôležitejšie skupiny algoritmov patria:
Collections.sort(List<T> list) zoradí zoznam v čase O(n log n). Metóda Collections.reverse(List<?> list) otočí poradie prvkov a Collections.shuffle(List<?> list) ich náhodne premieša.Collections.max() a Collections.min() dokážeš rýchlo nájsť najväčší alebo najmenší prvok na základe porovnávania objektov.Collections.unmodifiableList(...)obalia existujúcu kolekciu a zablokujú akékoľvek pokusy o modifikáciu vyvolaním UnsupportedOperationException. To je dôležité pre zapuzdrenie dát v tvojich objektochList<String> frameworkNames = new ArrayList<>();
frameworkNames.add("Spring");
frameworkNames.add("Quarkus");
frameworkNames.add("Micronaut");
// Bezpečné uzamknutie kolekcie pre zápis
List<String> readOnlyList = Collections.unmodifiableList(frameworkNames);
// Akýkoľvek pokus o readOnlyList.add("Micronaut") teraz zlyhá za behu
Od verzie Java 8 sú kolekcie natívne prepojené s Java Stream API prostredníctvom metódy stream(), ktorú definuje priamo rozhranie Collection. Stream API však nenahrádza kolekcie. Kolekcie slúžia na držanie a organizáciu reálnych dát v pamäti, zatiaľ čo streamy slúžia na ich deklaratívne spracovanie a transformáciu.
Hlavnou výhodou prepojenia JCF a Stream API je čitateľnosť kódu. Komplexné filtrovanie, mapovanie typov a agregáciu dokážeš zapísať ako jeden plynulý reťazec operácií.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// Deklaratívne filtrovanie a transformácia dát z kolekcie
List<String> evenNumbersStrings = numbers.stream()
.filter(n -> n % 2 == 0) // párne čísla
.map(n -> "Číslo: " + n) // int → String
.collect(Collectors.toList()); // výsledok do List
Streamy navyše umožňujú triviálny prechod na paralelné spracovanie pomocou metódy parallelStream(), kedy sa operácie nad prvkami kolekcie automaticky rozdelia medzi dostupné jadrá procesora pomocou ForkJoinPool, čo výrazne zrýchľuje spracovanie masívnych dátových objemov.
Používanie parallelStream() však nie je univerzálne zrýchlenie. Pri malých kolekciách alebo pri I/O operáciách môže dokonca výkon zhoršiť kvôli réžii spojenej so správou vlákien.
Optimalizácia práce s kolekciami v reálnych produkčných aplikáciách si vyžaduje dodržiavanie pravidiel, ktoré minimalizujú pamäťovú réžiu a predchádzajú zbytočným chybám pri behu programu.
Ak vieš, že do zoznamu ArrayList alebo mapy HashMap budeš vkladať presne 1000 prvkov, definuj to hneď pri volaní konštruktora new ArrayList<>(1000). Predídeš tým postupnému internému zväčšovaniu poľa, ktoré vyžaduje alokáciu novej pamäte a zbytočné kopírovanie dát.
Vždy definuj typ premennej, návratový typ metódy alebo typ parametra ako rozhranie (List, Set, Map), nie ako reálnu triedu (ArrayList, HashSet, HashMap). Umožní ti to kedykoľvek zmeniť internú dátovú štruktúru bez zásahu do biznis logiky aplikácie.
Ak metóda vracia zoznam alebo množinu a nenašla žiadne výsledky, nikdy nevracaj null. Vždy vráť prázdnu kolekciu, ideálne pomocou optimalizovaných konštánt Collections.emptyList(), Collections.emptySet() alebo Collections.emptyMap(). Týmto krokom ochrániš volajúci kód pred rizikom vzniku NullPointerException a odstrániš nutnosť písať zbytočné kontroly na hodnoty null.
Ak používaš vlastné objekty ako kľúče v HashMap alebo prvky v HashSet, musíš striktne dodržať zmluvu metód equals()ahashCode()
. Ak dve inštancie považuje metóda <code“>equals()za identické, ich hashCode()musí vracať rovnakú celočíselnú hodnotu. V opačnom prípade tvoja kolekcia nebude schopná prvok vyhľadať a dôjde k duplikácii dát alebo k ich strate.

Ak migruješ starší kód, prejdi všetky verejné metódy a typy návratových hodnôt zmeň z konkrétnych tried (ArrayList, HashMap) na rozhrania (List, Map). Otvorí ti to dvere k bezbolestnému prechodu na výkonnejšie implementácie ako ConcurrentHashMap alebo CopyOnWriteArrayList.
Dôvod spočíva v rozdielnosti ich dátových modelov. Rozhranie Collection spravuje sekvenciu alebo skupinu samostatných, izolovaných prvkov. Rozhranie Map pracuje s pármi kľúč-hodnota. Metódy definované v rozhraní Collection, ako napríklad add(E e, nie sú kompatibilné s architektúrou mapy, pretože mapa bezpodmienečne vyžaduje pre uloženie dvojicu dát súčasne pomocou put(K key, V value).
HashMap nie je synchronizovaná, povoľuje vložiť jeden kľúč s hodnotou nulla ľubovoľný počet hodnôt null. Hashtable je historická legacy trieda, ktorej všetky metódy sú synchronizované, čo spôsobuje stratu výkonu. Hashtable navyše striktne zakazuje akékoľvek nullkľúče aj hodnoty. V modernom kóde sa Hashtable nepoužíva a nahrádza ju buď HashMap (pre jednovláknové prostredie) alebo ConcurrentHashMap (pre viacvláknové prostredie).
Vždy, keď potrebuješ dátovú štruktúru typu zásobník (LIFO). Trieda Stack rozširuje triedu Vector, čo je architektonická chyba. Zdedila kvôli tomu zbytočnú synchronizáciu všetkých metód a indexovaný prístup, ktorý pri zásobníku nedáva zmysel. ArrayDeque nie je synchronizovaná, interne rotuje indexy nad kruhovým poľom, nevytvára overhead s uzlami a je výrazne rýchlejšia a pamäťovo efektívnejšia.
Implementácie HashSet a LinkedHashSet dovoľujú vložiť maximálne jeden prvok s hodnotou null. Avšak TreeSet hodnotu null nepovoľuje. Pri vložení null do TreeSet dôjde k okamžitému vyvolaniu výnimky NullPointerException, pretože táto štruktúra neustále porovnáva prvky medzi sebou, aby ich udržala usporiadané a nad hodnotou null nie je možné zavolať metódu compareTo().
Hoci oba prístupy slúžia na vytvorenie zoznamu, do ktorého nie je možné pridávať alebo z neho mazať prvky, fungujú úplne inak: Collections.unmodifiableList() vracia iba nemenný pohľad (view) nad pôvodným zoznamom. Ak pôvodný zoznam (napríklad ArrayList) neskôr modifikuješ, táto zmena sa premietne aj do tohto neupraviteľného pohľadu. List.of() (predstavené v Java 9) vytvára skutočne nemennú (immutable) inštanciu kolekcie, ktorá si vytvára vlastnú kópiu dát. Pôvodný zdroj už na ňu nemá žiadny vplyv a navyše táto implementácia striktne zakazuje vkladanie null hodnôt.
Keď dva odlišné kľúče vygenerujú rovnaký hashCode, nastáva kolízia a objekty padnú do rovnakého pamäťového bucketu. V starších verziách Javy sa kolízie riešili pomocou prepojeného zoznamu (LinkedList) vnútri bucketu, čo pri veľkom počte kolízií degradovalo výkon z z O(1) na O(n).
Od verzie Java 8 bol predstavený mechanizmus treeification. Ak počet prvkov v jednom buckete presiahne hodnotu 8 (TREEIFY_THRESHOLD)a celková kapacita mapy je aspoň 64, prepojený zoznam sa automaticky transformuje na vyvážený červeno-čierny strom. Časová zložitosť v najhoršom prípade tak klesne na O(log n).
Oba nástroje slúžia na definovanie pravidiel pre radenie kolekcií, no líšia sa v mieste implementácie:
Comparable definuje prirodzené radenie objektov. Trieda musí implementovať metódu compareTo(). Objekt tak vie sám seba porovnať s iným objektom rovnakého typu (napríklad trieda String alebo Integer).
Comparator predstavuje externú logiku radenia. Implementuje sa ako samostatná trieda alebo lambda výraz s metódou compare(). Používa sa vtedy, keď nemáš prístup k zdrojovému kódu triedy, alebo keď chceš rovnakú kolekciu objektov zoradiť viackrát podľa úplne odlišných kritérií (napríklad raz podľa mena a raz podľa veku).
Pohľad je špeciálna kolekcia, ktorá nevlastní svoje vlastné dáta v pamäti, ale iba odkazuje na časť inej, materskej kolekcie. Akákoľvek zmena vykonaná v pohľade priamo modifikuje pôvodnú kolekciu a naopak.
Typickými príkladmi sú metóda subList(int fromIndex, int toIndex)na rozhraní List alebo metódy keySet() a values() na rozhraní Map. Pri práci s pohľadmi si musíš dávať pozor na štrukturálne zmeny pôvodnej kolekcie, ktoré môžu spôsobiť zneplatnenie pohľadu a vyvolanie výnimiek.
Java Collections Framework je jedným z najprepracovanejších a najdôležitejších pilierov celého jazyka Java. Úspech pri navrhovaní výkonných aplikácií nespočíva v tom, že si dokážeš napísať vlastnú dátovú štruktúru, ale v tom, že vieš presne identifikovať, ktorú z existujúcich implementácií kedy použiť.
Zvolením správneho rozhrania a konkrétnej triedy priamo ovplyvňuješ rýchlosť spracovania dát, pamäťovú náročnosť a v konečnom dôsledku aj stabilitu celého systému vo viacvláknovom prostredí. Používaj tento článok ako svoju referenčnú príručku, a keď si budeš potrebovať občerstviť svoje nadobudnuté JCF vedomosti, vráť sa k jednotlivým sekciám.
Ak sa chceš dozvedieť viac o fungovaní konkrétnej dátovej štruktúry, pozri si (alebo stiahni) praktické ukážky kódu, klikni na príslušný odkaz v našom dashboarde a prečítaj si detailný článok o danej kolekcii.

Súvisiace články
