




Java programmer expert

In today’s digital world, data has become one of the most valuable commodities, whether it is social networks that analyse billions of interactions between communicating people every day in the virtual space of the Internet, medical systems that store information about patients and diseases who have come to the doctor for an examination, or digital trading instruments such as Bitcoin, which is now hitting the magical level of one hundred thousand dollars per Bitcoin.

V článku sa dozvieš:
Data is ubiquitous and is becoming a driving force for innovation in all areas of human activity. But using it effectively requires an understanding of its structure and processing – which brings us to data structures. Data itself would be useless to us if we did not know how to organise, store and process it effectively.
Imagine a library without any system for arranging books – a chaos in which it is almost impossible to find what we are looking for. Similarly, the world of computer systems could not cope with the current volume of data, without well thought out and optimised data structures.
These structures, which are an invisible architecture for us users, are responsible for the correct categorization of data, storage and processing in such a way that, for example, a secretary working with office software, a player of the latest computer game, a customer shopping during Black Friday in an online store, or a query programmer in a large database, bring almost instantly exactly the data that they need or expect at that moment in time.
In this article, we delve into the fascinating world of data structures. We’ll talk about the basic ones like arrays and lists. From the basic ones, like arrays and lists, to the advanced ones, like hash tables or binary trees, we’ll show how each plays a key role in solving a variety of computational problems. You’ll learn why some structures are ideal for fast searches, others for storing large amounts of data, and still others for dynamic data management.
Whether you’re a budding programmer, a curious computer science student looking to better understand the fundamentals of your future craft, or already working in the IT field, this article will give you a practical insight into the importance of choosing the right data structures.
By not understanding the key features, strengths and weaknesses of a given data structure and using them inappropriately and inefficiently, we not only waste valuable data processing time, but also waste hardware resources. As we all know, time is money and, for example, a slow response when searching for goods on an e-shop (by this we mean processing and filtering data according to the user’s criteria) has already discouraged more than one customer from making a purchase.
Data isn’t just meaningless binary numbers or text made up of weird ASCII characters – it’s the foundation of our lives. The world of modern technology is powered by data, efficient data structures and algorithms, and this article will introduce you to some of them.
Data are the building blocks of information. They are ordinary facts, numbers, texts, symbols, sounds or images that have no concrete meaning without context. We can think of them as individual pieces of a puzzle – individually they are only small parts of a whole, but when arranged correctly, they can form a beautiful picture or become the solid foundation of something bigger.
The data can be structured as follows:
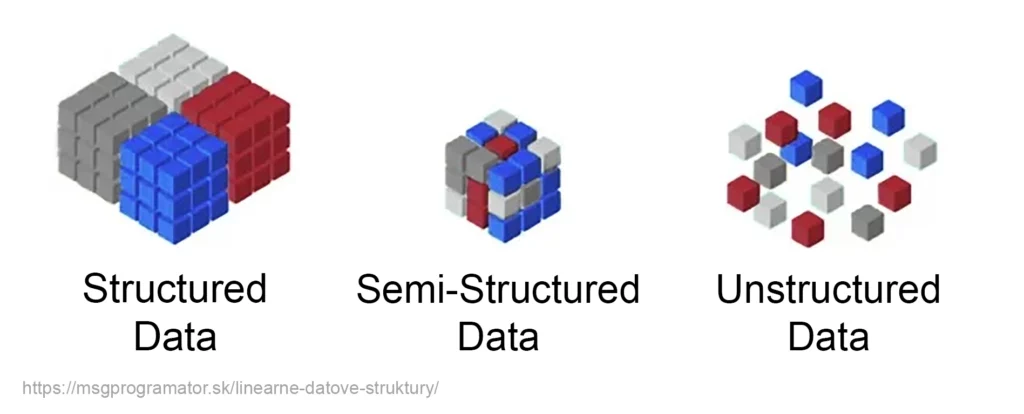
Data forms the basis of all decisions in the modern world. Companies use it for market analysis, scientists use it for research, doctors use it for diagnosis and treatment, and governments use it for budget planning. Artificial Intelligence (AI) as we know it today would never have come about without it. Thanks to technologies that enable the collection, processing and analysis of vast amounts of data, we are now able to uncover patterns, make predictions and use statistics to find new knowledge that would otherwise remain hidden.
Data structures represent a way of organizing, storing, and processing data so that it can be used efficiently in computer programs. They give data a particular form and determine how the data will be arranged, but also how it can be manipulated. They are the basic building blocks of a program.
We always try to optimize the speed of operations such as data search, retrieval and writing when designing a data structure or selecting an existing one. A secondary thing to keep in mind is that efficient data structures should minimize memory footprint. This includes not only the space for storing data, but also auxiliary structures, indexes or metadata that help in faster retrieval of the currently requested information. The implementation of the data structure should be as simple as possible for the data in question to eliminate the risk of errors. It is also essential to design the data structure to be flexible and easily extensible for different applications.
Efficient selection and implementation of data structures has a major impact on the complexity of the algorithms that use them and thus the overall performance of the application.
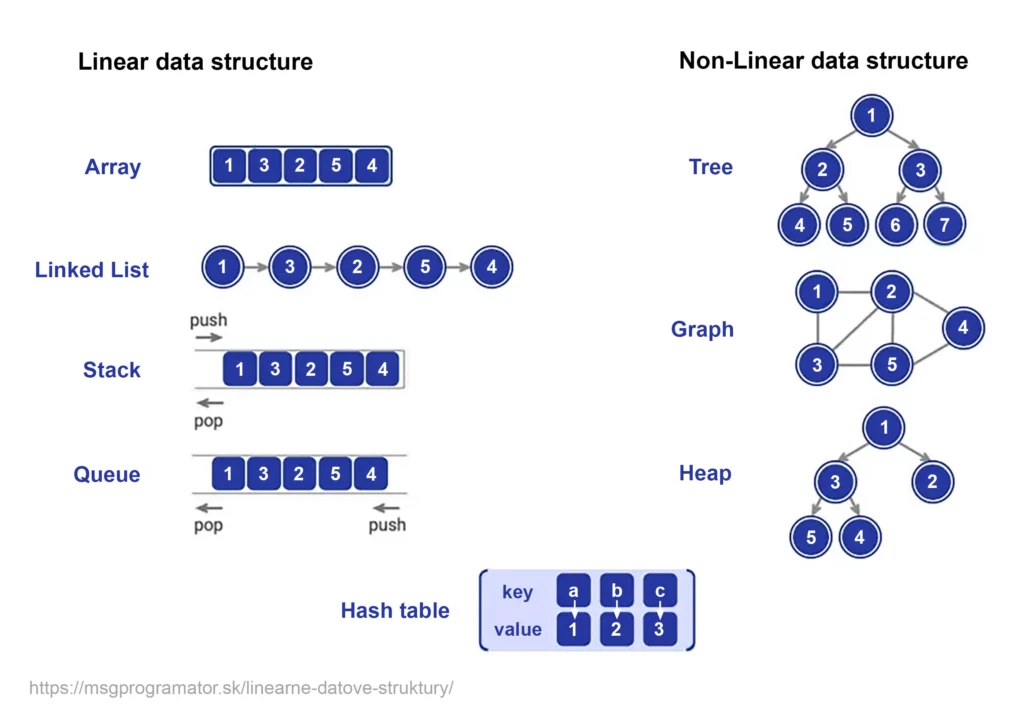
Data structures can be divided according to their data storage architecture into:
Search – any element in the data structure can be searched.
Insert – inserting a new element into the data structure.
Update – replacing an element with another element in the data structure.
Delete – removing an existing element from the data structure.
Sort – elements of the data structure can be sorted either ascending or descending. In our past articles, we have exhaustively covered data sorting and sorting algorithms.
A data structure is sometimes mistaken for an abstract data type (ADT).
The ADT says what is to be done, and the data structure says how it is to be done. In other words, we can say that the ADT provides us with the design, while the data structure provides the implementation part. In a particular ADT, different data structures can be implemented. For example, The ADT stack can use an array or linked list data structure at the data level. The decision of what to use is up to the programmer and their specific requirements.
We will now discuss in detail linear data structures, their basic properties, types, advantages and disadvantages, as well as the most common use cases/examples.
In programming, arrays are one of the most expensive and widely used data structures. They store elements in a contiguous block of memory, with each element accessible by a numeric index. While arrays offer an access time of O(1), which is excellent for read-intensive operations, the efficiency of write operations (insertion and deletion) can vary greatly depending on the location of the operation in the array and the overall size of the array.
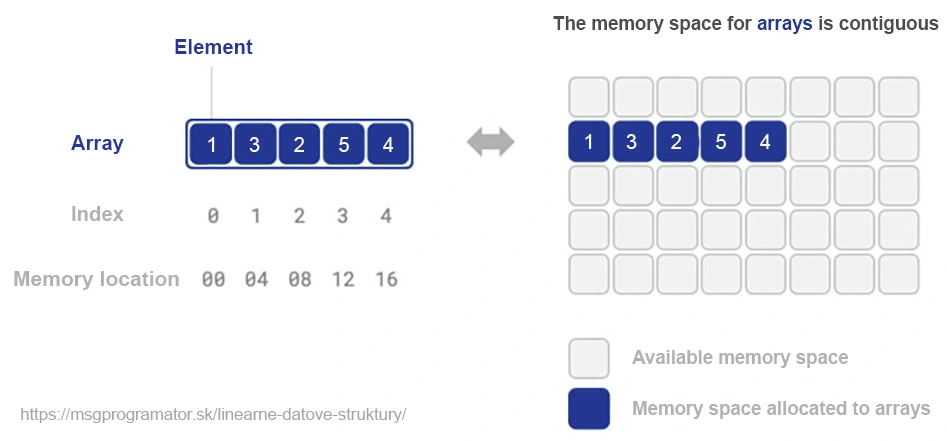
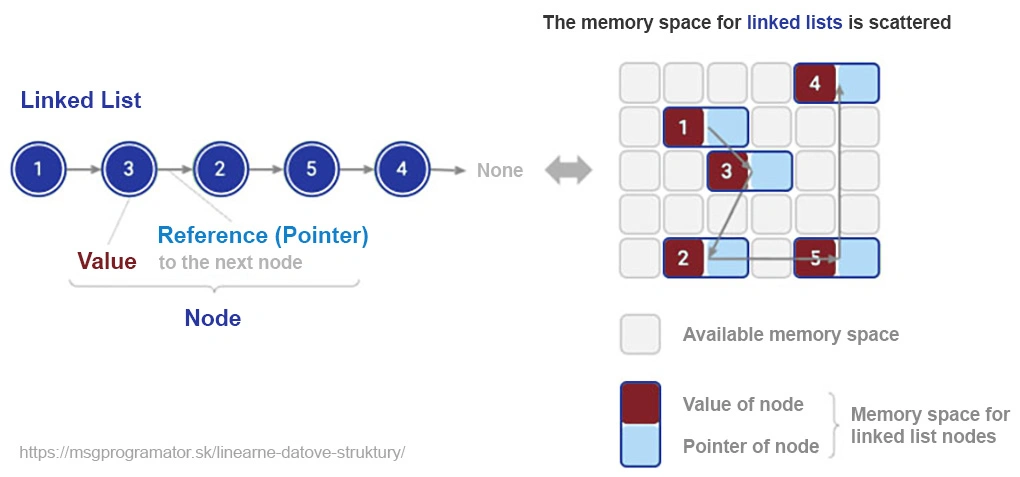
A linked list is a basic data structure that is distinguished from an array by its dynamic nature and flexibility. Unlike arrays, which require a contiguous block of memory, a linked list consists of nodes scattered in memory, with each node containing a value and a reference (pointer) to the next node. This feature allows easy manipulation of elements, but at the cost of lower efficiency for direct access.
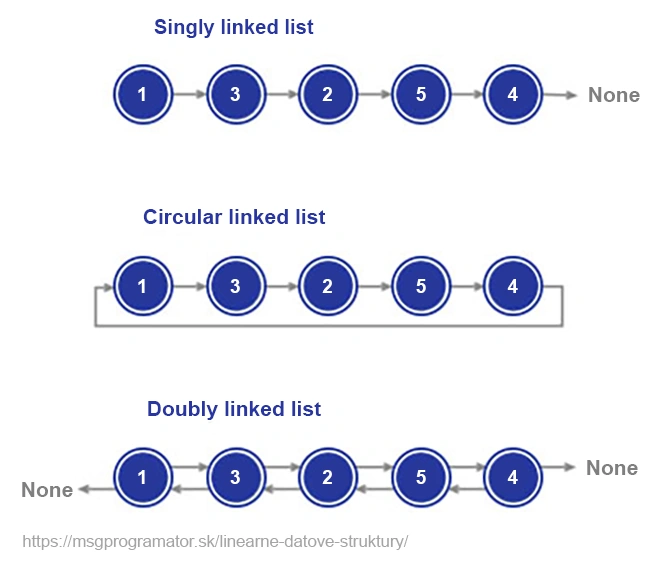
Imagine managing your history in a browser. Each visited site is stored as a node in a list. When you go back to the previous page, you simply move to the previous node, an ideal example where the list excels. Lists are indispensable for tasks requiring flexibility and dynamic data operations, despite not being suitable for all types of tasks.
The stack is one of the basic data structures that works on the principle of “Last In, First Out” (LIFO). Think of it as a set of plates stacked on top of each other – we always add a new plate on top and always reach for the top one when removing it. This simple but extremely useful structure has a wide range of applications in programming and computer science.
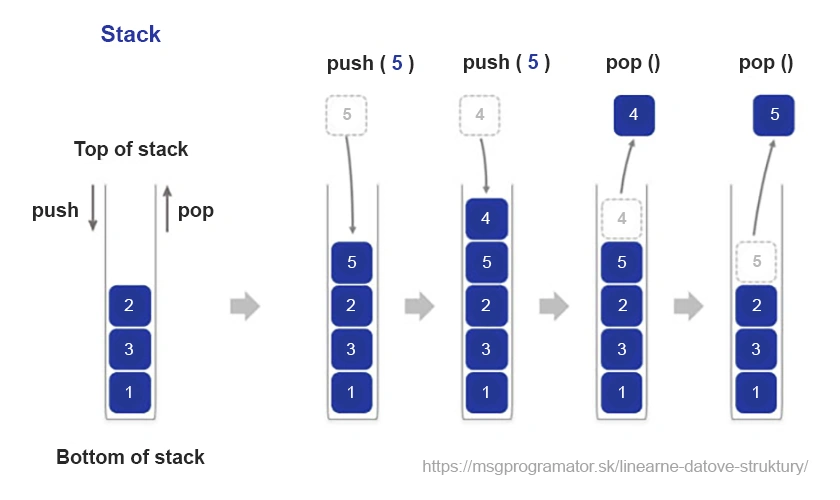
Imagine a text editor with a back function. Every change we make is added to the stack. When we click “undo”, the last change is removed and our document returns to its previous state.
While stacks are specific in their simplicity and limitations, these features make them indispensable in many applications and algorithms where the order of execution of operations must be precisely preserved. For more information, read the Java Stack article .
A queue is a basic data structure that operates on a first in, first out (FIFO) basis. It can be thought of as a queue of orders waiting to be processed – the first one to arrive will also be the first to be processed. This structure is extremely useful in situations where it is important to maintain the order of processing.
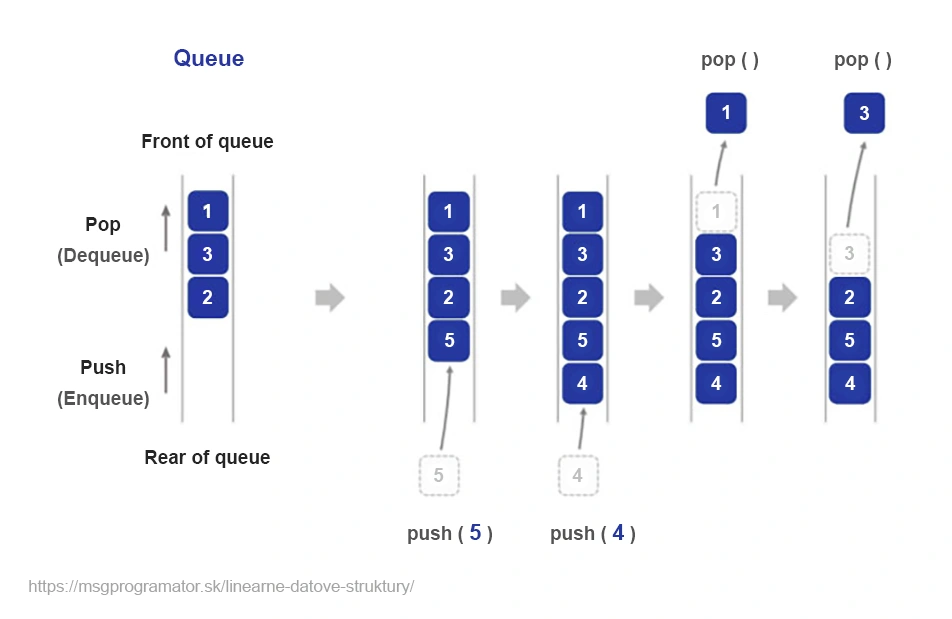
Imagine a supermarket checkout. Every customer who comes in is placed at the end of the queue (enqueue). The cashier always serves the customer at the front of the queue (dequeue). This process preserves the order of arrival of customers.
Queues are useful wherever tasks or data need to be processed efficiently in the order they arrive. Despite the limitations of their sequential approach, they are one of the most important structures in programming.
We will now discuss in detail non-linear data structures, their basic properties, types, advantages and disadvantages, as well as the most common use cases/examples.
A tree is a basic nonlinear data structure that organizes data hierarchically. It consists of nodes, where each node has one parent node – the parent (excluding the root node) and may have zero or more child nodes – the children. This structure enables efficient data processing, especially in searching, sorting and representing relationships.
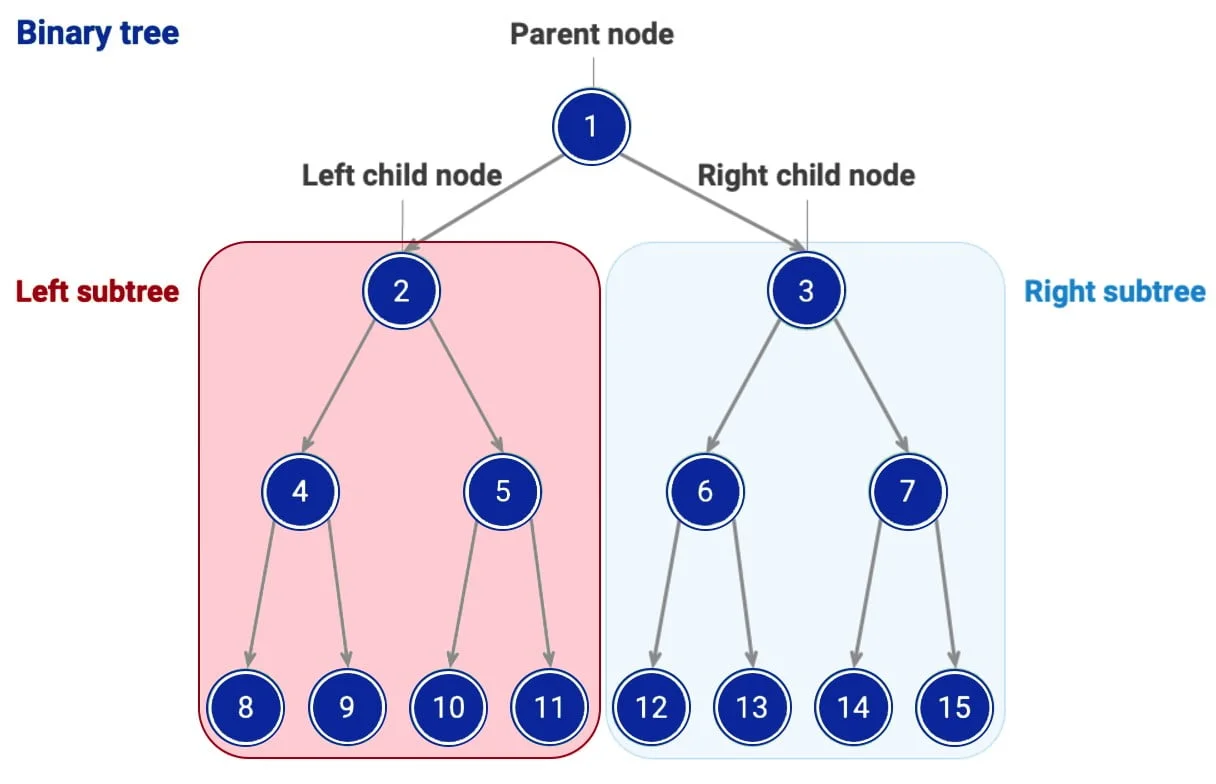
Hierarchical structure: trees are arranged in hierarchical layers, with the root at the top and the nodes below it representing the next levels.
Nodes and edges: each node contains data and links to its child nodes. Edges represent connections between nodes.
Root: It is the highest node of a tree that has no parent node.
Leaves: are nodes that have no children (also known as terminal nodes).
Height of the tree: The number of edges on the longest path from root to leaf.
Binary tree: each node can have at most two descendants – a left and a right node.
Binary Search Tree (BST): a binary tree where the left subtrees contain values less than a node and the right subtrees contain values greater than a node.
Balanced Trees: trees, such as AVL or red-black trees, that maintain a balanced height for more efficient operations.
N-ary tree: nodes can have up to N child nodes.
Trie: Specialized tree for efficient searching, for example when working with words or prefixes.
Imagine a family tree – the root of the tree represents the oldest ancestor and the nodes below represent its descendants. This hierarchy is a direct example of using a tree to organize and clearly represent data.
Trees are one of the most important data structures in computer science. Their ability to model complex relationships and efficiently manipulate hierarchical data makes them an integral part of modern algorithms and applications.
A graph is a non-linear data structure that represents objects (nodes, called vertices) and the relationships between them (called edges). This structure is extremely versatile and is used to model a variety of situations such as social networks, traffic maps, or relationships between entities in databases.
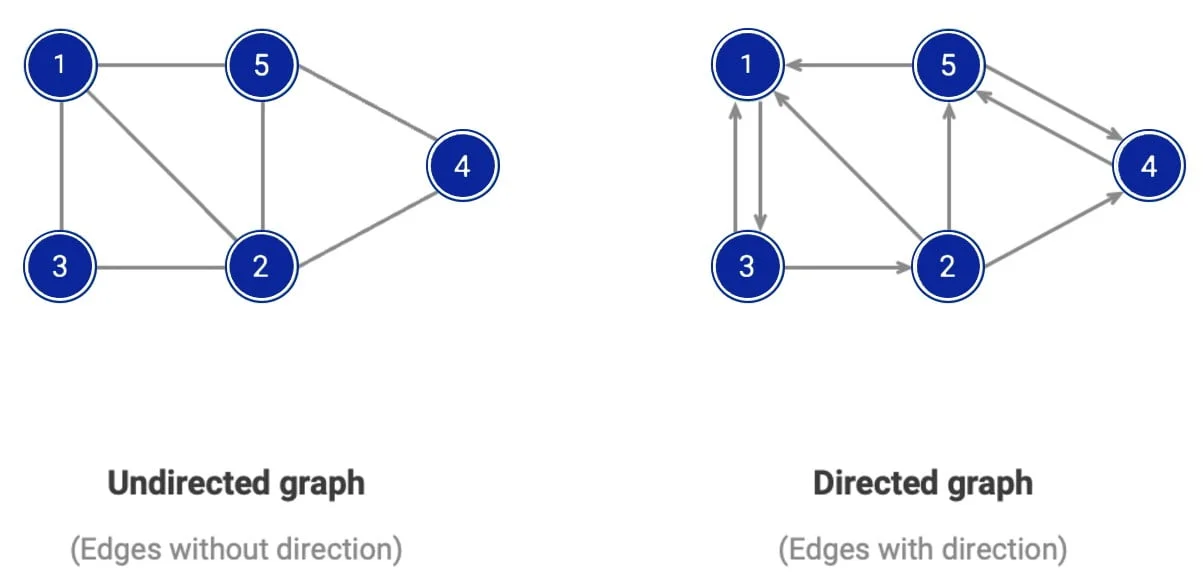
Vertices (Nodes): the basic parts of the graph that represent objects or entities.
Edges: connections between vertices that represent relationships or interactions.
Orientation: the graph can be oriented (directed edges, e.g. a one-way street) or non-oriented (no direction, e.g. a two-way road).
Edge weighting: some charts contain weights on the edges to represent values such as distances, costs or time.
Undirected Graph: edges have no direction, the connection between two vertices is mutual.
Directed Graph or Digraph: Edges have a direction and connect vertices in a specific order.
Weighted Graph: the edges are assigned a value (weight).
Cyclic Graph: contains closed paths (cycles).
Acyclic Graph: contains no cycles.
Tree Graph or Tree: a special case of an acyclic graph where each vertex is accessible via a single path.
Connected Graph: there is a path between every two vertices.
Imagine an urban transport network. Each place (stop) is a vertex and the connection between stops is an edge. To find the fastest path between two places, we use an algorithm that traverses the graph and identifies the shortest route.
Graphs are indispensable in solving complex problems where it is crucial to understand and be able to analyse the relationships between objects. Thanks to their versatility and the rich possibilities of their application, they have become the basis of many areas of modern computer science.
Now we will discuss in detail the tabular data structures, their basic properties, types, advantages and disadvantages, as well as the most common use cases/examples.
A hash table is a data structure that implements an associative array in which values (data) are stored and retrieved based on a unique key. It uses a hash function that converts the key to an index in the array, thus allowing efficient storage and access to the data.
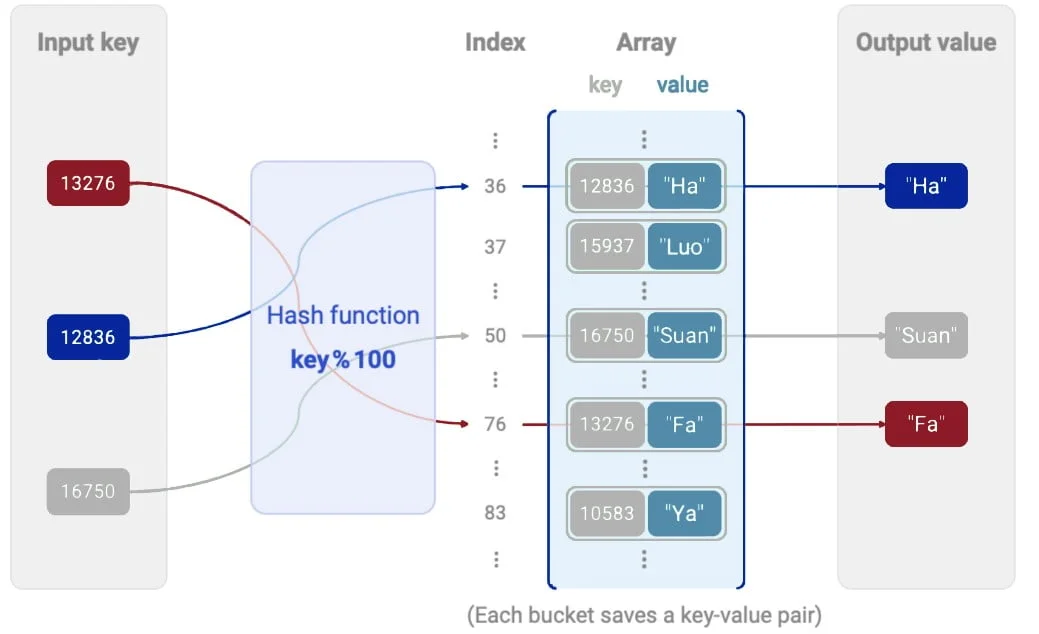
Hashing function: the key is converted to an index in the corresponding field using this function. The quality of the hash function determines the performance of the table.
Unique keys: each record in the table is assigned a unique key.
Collisions: if two different keys generate the same index, a collision occurs, which is resolved by specific techniques (e.g., separate chaining).
Separate chaining: each index in the table contains a list or other structure that stores all values with the same index.
Open addressing: if a collision occurs, another free slot is searched for according to a certain pattern (e.g. linear or quadratic probing).
Imagine a phone book in which you want to quickly look up a person’s number based on their name. The person’s name serves as a key, which is converted to an index using the hash function. The corresponding phone number is stored on this index.
Hash tables are a powerful and efficient structure for a wide range of applications where fast access to data is a priority. Their ability to efficiently process large amounts of data makes them indispensable throughout the IT field.
I would still like to briefly mention at least some of the lesser known data structures that we may encounter in IT.
A binary tree that satisfies the following condition (each parent node is larger or smaller than its children). It is used to implement priority queues or in the Heap Sort algorithm, which we have already introduced on our blog.
A trie is a tree table structure optimized for string search, where each node represents a part of a key. It is used in word processors, autocomplete, or database searching.
It is used to represent and manage sets with disjunctive elements. It is used in graph algorithms such as the Kruskal algorithm.
A tree designed to efficiently solve problems associated with intervals and ranges of data. It is suitable for quick operations to determine the sum, minimum or maximum of a range.
Efficient structure for updating and searching sums in sequences. It is used in tasks that compute ranges.
A specialized tree for organizing points in K-dimensional space. It is used in algorithms for image processing, computer vision, and database search.
Represents all suffixes of a given string. It is particularly effective in substring search and text-based algorithms.
Matrix tables are two-dimensional or multi-dimensional arrays that store data in rows and columns. It is used, for example, in linear algebra for working with matrices.
A two-dimensional matrix where the rows and columns represent the vertices of the graph and the values in the matrix indicate the existence of edges between vertices. It is used to efficiently represent dense graphs and to quickly detect the existence of an edge between two vertices.
A list where each vertex of the graph contains a list of all its neighboring vertices. Ideal for representing sparse graphs, as it saves memory compared to a neighborhood matrix.
Structure for storing matrices with most zero values, where only non-zero values and their positions are stored. It is used in areas such as machine learning, graph analysis, and modeling large sparse data structures.
A hash table-like structure that resolves collisions in an alternative way of key dispersion. Efficient for handling large volumes of data with lower risk of clustering collisions in hash structures.
Data structures are an essential part of programming because they provide a way to efficiently organize, process, and manipulate data. Linear data structures (queue, stack, linked list, array) have specific advantages, disadvantages, and areas of application.
Their proper selection and implementation can significantly affect the performance and efficiency of the software. Therefore, understanding the basic principles of data structures is crucial for anyone who wants to delve deeper into programming, algorithms or databases, so that they can use this knowledge to create optimized and innovative solutions.
If you’re looking for a job and you’re a Java developer, check out our employee benefits and respond to our job offers!

Related articles
