




Java Entwickler Experte

In der heutigen digitalen Welt sind Daten zu einer der wertvollsten Ressourcen geworden. Egal ob es sich um soziale Netzwerke handelt, die täglich Milliarden von Interaktionen zwischen Menschen im virtuellen Raum des Internets analysieren, um Gesundheitssysteme, die Informationen über Patienten und Krankheiten speichern, die einen Arzt aufsuchen, oder um digitale Handelsinstrumente wie Bitcoin, der gerade die magische Grenze von 100.000 Dollar pro Bitcoin erreicht.

In diesem Artikel erfährst du:
Daten sind allgegenwärtig und treiben Innovationen in allen Bereichen menschlicher Aktivität voran. Ihre effektive Nutzung erfordert jedoch ein Verständnis ihrer Struktur und Verarbeitung – und genau hier kommen die Datenstrukturen ins Spiel. Daten an sich wären nutzlos, wenn wir nicht wüssten, wie wir sie effizient organisieren, speichern und verarbeiten können.
Stellen wir uns eine Bibliothek ohne jegliches System zur Ordnung der Bücher vor – ein Chaos, in dem es nahezu unmöglich ist, das Gesuchte zu finden. Ähnlich wäre die Welt der Computersysteme nicht in der Lage, das heutige Datenvolumen zu bewältigen, ohne durchdachte und optimierte Datenstrukturen.
Diese Strukturen, die für uns Nutzer eine unsichtbare Architektur darstellen, sind verantwortlich für die korrekte Kategorisierung, Speicherung und Verarbeitung von Daten, sodass z. B. die Sekretärin, die mit Bürosoftware arbeitet, der Spieler eines aktuellen Computerspiels, der Kunde, der während des Black Friday im Online-Shop einkauft, oder der Programmierer, der Abfragen in einer großen Datenbank durchführt, erhielten fast sofort genau die Daten, die sie im jeweiligen Moment benötigten oder erwarteten.
In diesem Artikel tauchen wir in die faszinierende Welt der Datenstrukturen ein. Wir werden uns mit den grundlegenden Strukturen wie Arrays und Listen befassen. Von den grundlegenden wie Arrays und Listen bis hin zu fortgeschrittenen wie Hash-Tabellen oder Binärbäumen zeigen wir, wie jede von ihnen eine Schlüsselrolle bei der Lösung verschiedener Berechnungsprobleme spielt. Du wirst erfahren, warum einige Datenstrukturen ideal für schnelles Suchen, andere für das Speichern großer Datenmengen und wieder andere für die dynamische Verwaltung von Daten geeignet sind.
Egal, ob du ein Anfänger in der Programmierung bist, ein neugieriger Informatikstudent, der die Grundlagen seines zukünftigen Handwerks besser verstehen möchte, oder bereits in der IT-Branche arbeitest, dieser Artikel bietet dir einen praktischen Einblick in die Bedeutung der richtigen Auswahl von Datenstrukturen.
Das Missverstehen der Schlüsselfunktionen, Stärken und Schwächen einer bestimmten Datenstruktur und ihre ungeeignete, ineffiziente Verwendung führt nicht nur zu wertvoller verlorener Verarbeitungszeit, sondern verschwendet auch Hardware-Ressourcen. Wie wir alle wissen, Zeit ist Geld, und zum Beispiel Langsame Reaktionszeiten bei der Produktsuche in einem Online-Shop (d.h. die Verarbeitung und Filterung von Daten basierend auf den vom Nutzer angegebenen Kriterien) haben bereits viele Kunden vom Kauf abgehalten.
Daten sind nicht nur bedeutungslose binäre Zahlen oder Text, der aus seltsamen ASCII-Zeichen besteht – sie sind die Grundlage unseres Lebens. Die Welt der modernen Technologien wird von Daten, effizienten Datenstrukturen und Algorithmen angetrieben, und dieser Artikel stellt dir einige davon vor.
Daten sind die Bausteine von Informationen. Sie sind gewöhnliche Fakten, Zahlen, Texte, Symbole, Klänge oder Bilder, die ohne Kontext keine konkrete Bedeutung haben. Wir können sie uns wie einzelne Teile eines Puzzles vorstellen – einzeln sind sie nur kleine Teile eines Ganzen, aber wenn sie richtig angeordnet sind, können sie ein schönes Bild ergeben oder die solide Grundlage für etwas Größeres werden.
Wir können die Daten auf der Grundlage der Strukturierung wie folgt unterteilen:
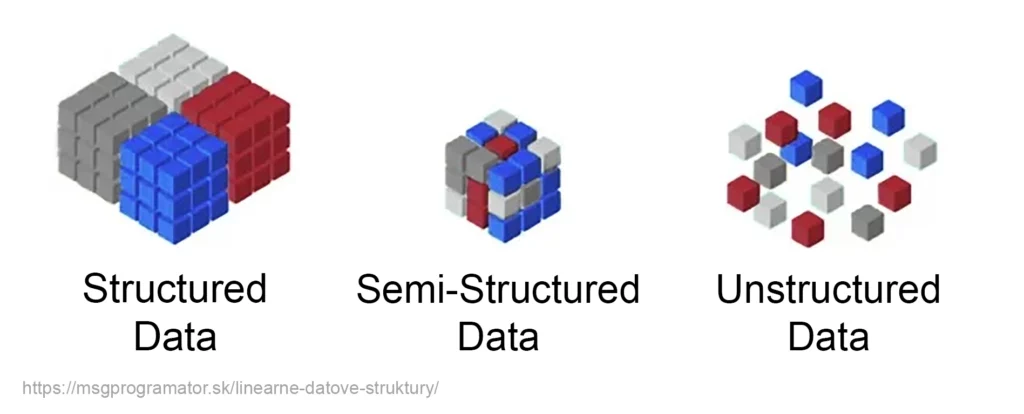
Daten bilden die Grundlage für alle Entscheidungen in der modernen Welt. Unternehmen nutzen sie für Marktanalysen, Wissenschaftler für die Forschung, Ärzte für die Diagnose und Behandlung und Regierungen für die Haushaltsplanung. Künstliche Intelligenz (KI), wie wir sie heute kennen, wäre ohne sie nicht möglich gewesen. Dank der Technologien, die die Erfassung, Verarbeitung und Analyse riesiger Datenmengen ermöglichen, können wir heute Muster aufdecken, Vorhersagen treffen und Statistiken nutzen, um neue Erkenntnisse zu gewinnen, die uns sonst verborgen bleiben würden.
Datenstrukturen stellen eine Möglichkeit dar, Daten zu organisieren, zu speichern und zu verarbeiten, damit sie in Computerprogrammen effizient genutzt werden können. Sie geben den Daten eine bestimmte Form und bestimmen, wie die Daten angeordnet werden, aber auch, wie sie manipuliert werden können. Sie sind die Grundbausteine eines Programms.
Beim Entwurf einer Datenstruktur oder bei der Auswahl einer bestehenden Struktur versuchen wir immer, die Geschwindigkeit von Vorgängen wie Datensuche, -abruf und -schreibung zu optimieren. Eine zweite Sache, die Sie im Auge behalten sollten, ist, dass effiziente Datenstrukturen den Speicherplatzbedarf minimieren sollten. Dazu gehört nicht nur der Speicherplatz für die Daten, sondern auch Hilfsstrukturen, Indizes oder Metadaten, die ein schnelleres Auffinden der aktuell angeforderten Informationen ermöglichen. Die Implementierung der Datenstruktur sollte für die betreffenden Daten so einfach wie möglich sein, um das Risiko von Fehlern auszuschließen. Außerdem ist es wichtig, die Datenstruktur so zu gestalten, dass sie flexibel und für verschiedene Anwendungen leicht erweiterbar ist.
Die effiziente Auswahl und Implementierung von Datenstrukturen hat einen großen Einfluss auf die Komplexität der Algorithmen, die sie verwenden, und damit auf die Gesamtleistung der Anwendung.
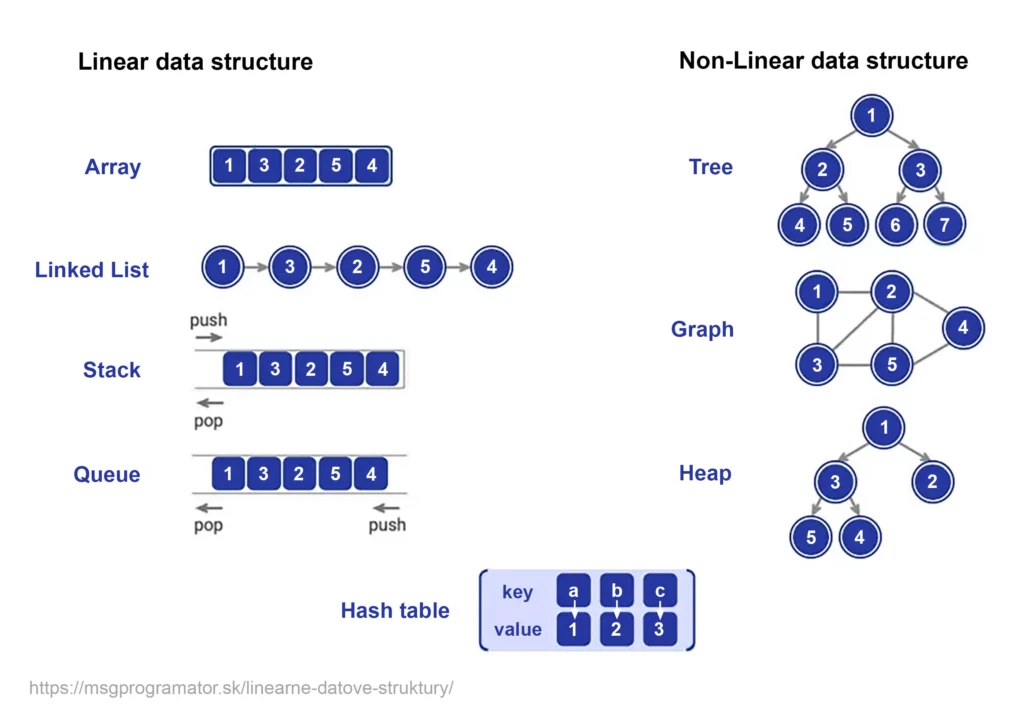
Datenstrukturen können nach ihrer Architektur der Datenspeicherung in folgende Kategorien unterteilt werden:
Suche – jedes Element in der Datenstruktur kann durchsucht werden.
Einfügen – Einfügen eines neuen Elements in die Datenstruktur.
Aktualisieren – Ersetzen eines Elements durch ein anderes Element in der Datenstruktur.
Löschen – Entfernen eines vorhandenen Elements aus der Datenstruktur.
Sortieren – Elemente der Datenstruktur können entweder aufsteigend oder absteigend sortiert werden. In unseren früheren Artikeln haben wir die Datensortierung und Sortieralgorithmen ausführlich behandelt.
Eine Datenstruktur wird manchmal mit einem abstrakten Datentyp (ADT) verwechselt.
Die ADT sagt, was zu tun ist, und die Datenstruktur sagt, wie es zu tun ist. Mit anderen Worten, wir können sagen, dass die ADT uns das Design liefert, während die Datenstruktur den Implementierungsteil liefert. In einer bestimmten ADT können verschiedene Datenstrukturen implementiert werden. Zum Beispiel. Der ADT-Stack kann auf der Datenebene eine Array- oder Linked-List-Datenstruktur verwenden. Die Entscheidung, was verwendet werden soll, liegt beim Programmierer und seinen spezifischen Anforderungen.
Wir werden nun im Detail auf lineare Datenstrukturen, ihre grundlegenden Eigenschaften, Typen, Vor- und Nachteile sowie die häufigsten Anwendungsfälle/Beispiele eingehen.
In der Programmierung sind Arrays eine der teuersten und am häufigsten verwendeten Datenstrukturen. Sie speichern Elemente in einem zusammenhängenden Speicherblock, wobei jedes Element über einen numerischen Index zugänglich ist. Während Arrays eine Zugriffszeit von O(1) bieten, was für leseintensive Operationen hervorragend ist, kann die Effizienz von Schreiboperationen (Einfügen und Löschen) je nach Position der Operation im Array und der Gesamtgröße des Arrays stark variieren.
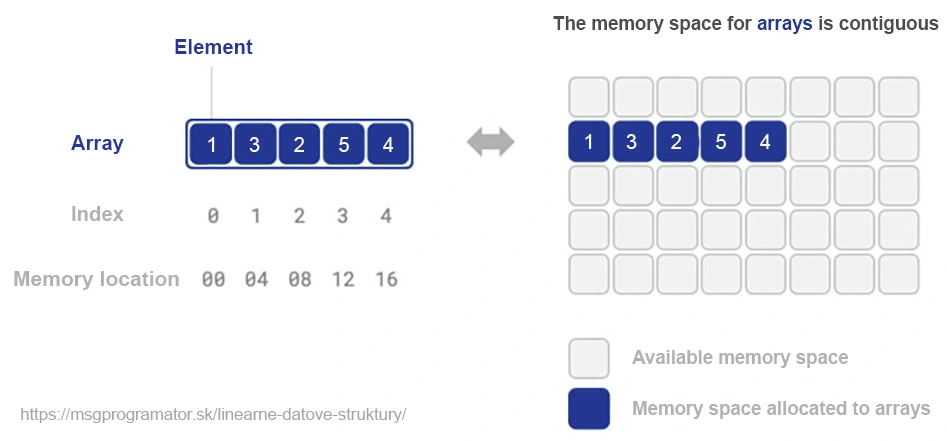
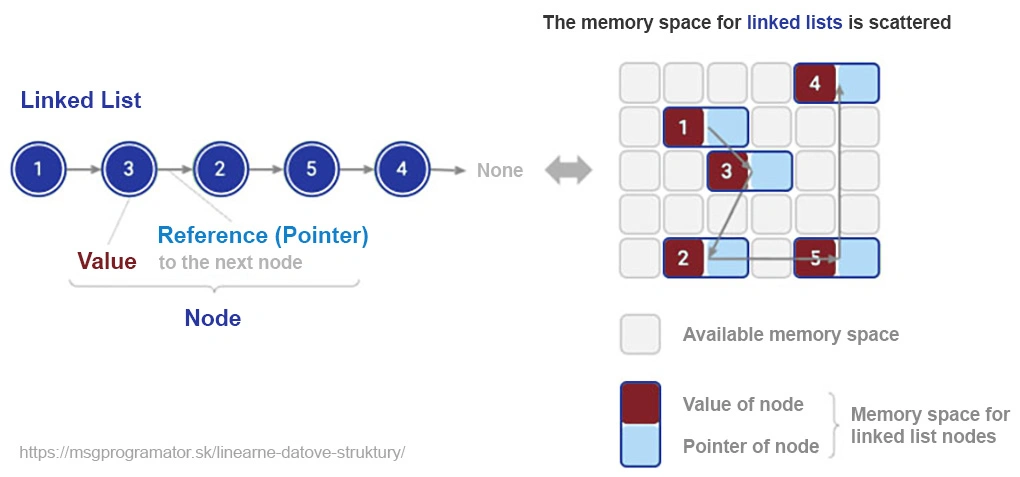
Eine verknüpfte Liste ist eine grundlegende Datenstruktur, die sich von einem Array durch ihre dynamische Natur und Flexibilität unterscheidet. Im Gegensatz zu Arrays, die einen zusammenhängenden Speicherblock benötigen, besteht eine verkettete Liste aus im Speicher verstreuten Knoten, wobei jeder Knoten einen Wert und einen Verweis (Pointer) auf den nächsten Knoten enthält. Diese Eigenschaft ermöglicht eine einfache Manipulation der Elemente, allerdings um den Preis einer geringeren Effizienz beim direkten Zugriff.
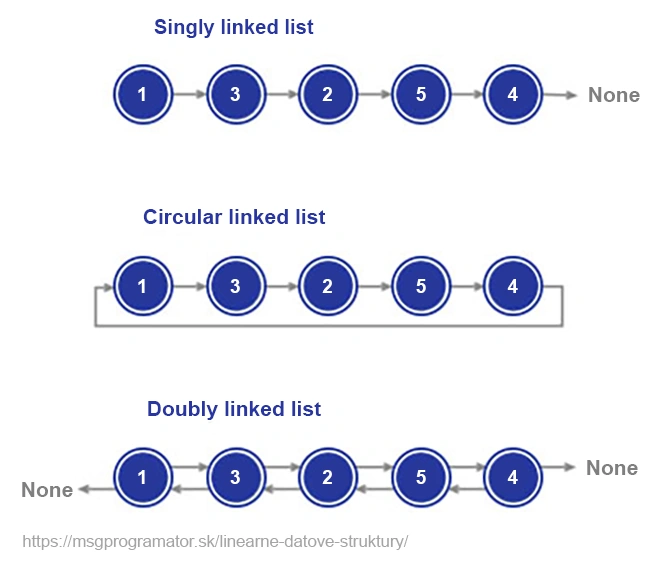
Stell dir die Historie eines Browsers vor. Jede besuchte Webseite wird als Knoten in einer Liste gespeichert. Wenn du zur vorherigen Seite zurückkehrst, bewegst du dich einfach zum vorherigen Knoten. Dies ist ein ideales Beispiel dafür, wie Listen ihre Stärke ausspielen. Listen sind unverzichtbar bei Aufgaben, die Flexibilität und dynamische Datenoperationen erfordern, obwohl sie nicht für alle Arten von Aufgaben geeignet sind.
Der Stapel ist eine der grundlegenden Datenstrukturen, die nach dem Prinzip „Last In, First Out“ (LIFO) funktioniert. Stellen wir uns den Stapel wie einen Satz übereinander gestapelter Teller vor – wir fügen immer einen neuen Teller oben hinzu und greifen immer nach dem obersten, wenn wir ihn entfernen. Diese einfache, aber äußerst nützliche Struktur hat eine Vielzahl von Anwendungen in der Programmierung und der Computerwissenschaft.
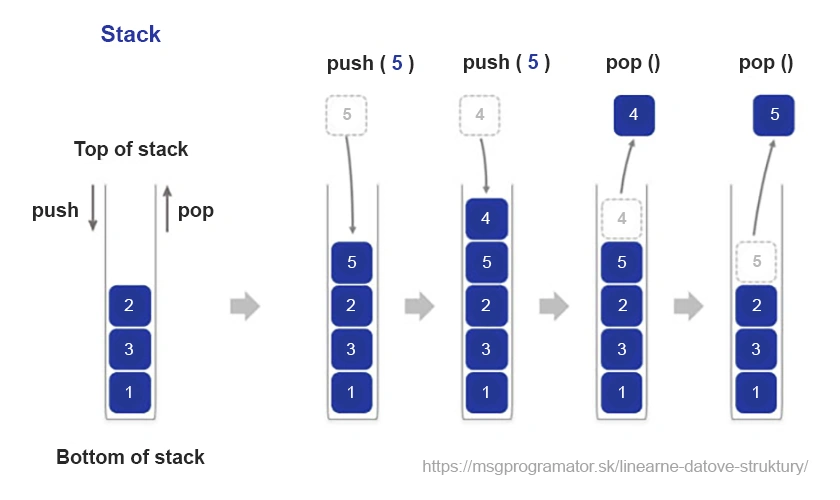
Stellen wir uns einen Texteditor mit einer Rückgängig-Funktion vor. Jede Änderung, die wir vornehmen, wird dem Stapel hinzugefügt. Wenn wir auf „Rückgängig“ klicken, wird die letzte Änderung entfernt und unser Dokument kehrt in seinen vorherigen Zustand zurück.
Stapel sind zwar in ihrer Einfachheit und ihren Beschränkungen spezifisch, aber diese Eigenschaften machen sie in vielen Anwendungen und Algorithmen unverzichtbar, bei denen die Reihenfolge der Ausführung von Operationen genau eingehalten werden muss. Weitere Informationen findest du im Artikel über den Java Stack.
Eine Warteschlange ist eine grundlegende Datenstruktur, die nach dem FIFO-Prinzip (first in, first out) arbeitet. Man kann sie sich als eine Warteschlange von Aufträgen vorstellen, die darauf warten, verarbeitet zu werden – der erste, der eintrifft, wird auch als erster verarbeitet. Diese Struktur ist äußerst nützlich in Situationen, in denen es wichtig ist, die Reihenfolge der Verarbeitung einzuhalten.
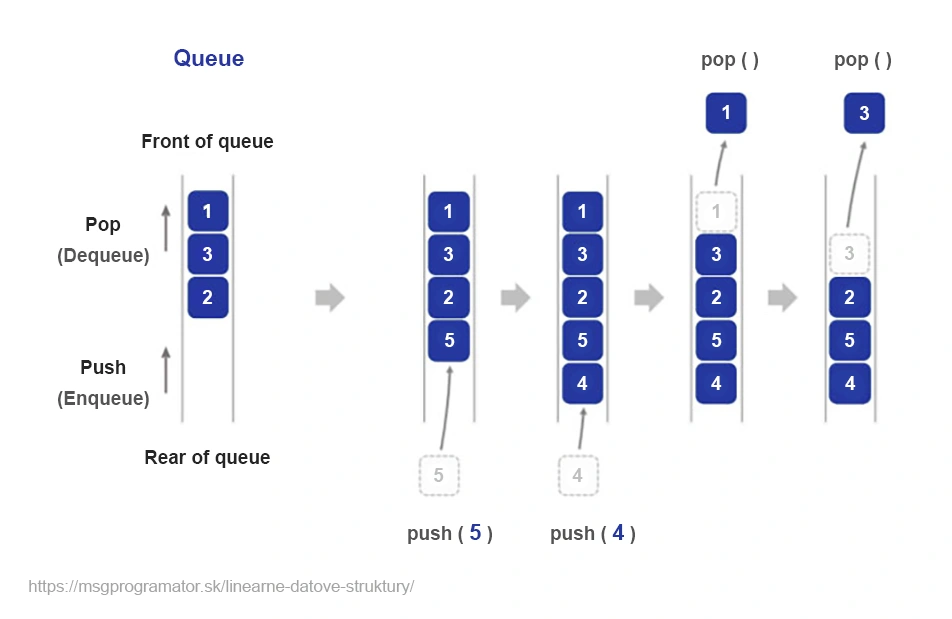
Stellen wir uns eine Supermarktkasse vor. Jeder Kunde, der hereinkommt, steht am Ende der Warteschlange (enqueue). Der Kassierer bedient immer den Kunden, der am Anfang der Warteschlange steht (dequeue). Bei diesem Verfahren bleibt die Reihenfolge der Ankunft der Kunden erhalten.
Warteschlangen sind überall dort nützlich, wo Aufgaben oder Daten in der Reihenfolge ihres Eintreffens effizient verarbeitet werden müssen. Trotz der Einschränkungen, die ihr sequenzieller Ansatz mit sich bringt, sind sie eine der wichtigsten Strukturen in der Programmierung.
Wir werden nun im Detail auf nicht-lineare Datenstrukturen, ihre grundlegenden Eigenschaften, Typen, Vor- und Nachteile sowie die häufigsten Anwendungsfälle/Beispiele eingehen.
Ein Baum ist eine grundlegende nichtlineare Datenstruktur, die Daten hierarchisch organisiert. Er besteht aus Knoten, wobei jeder Knoten einen übergeordneten Knoten – den Elternknoten (außer dem Wurzelknoten) –und null oder mehr untergeordnete Knoten – die Kindknoten – haben kann. Diese Struktur ermöglicht eine effiziente Datenverarbeitung, insbesondere beim Suchen, Sortieren und Darstellen von Beziehungen.
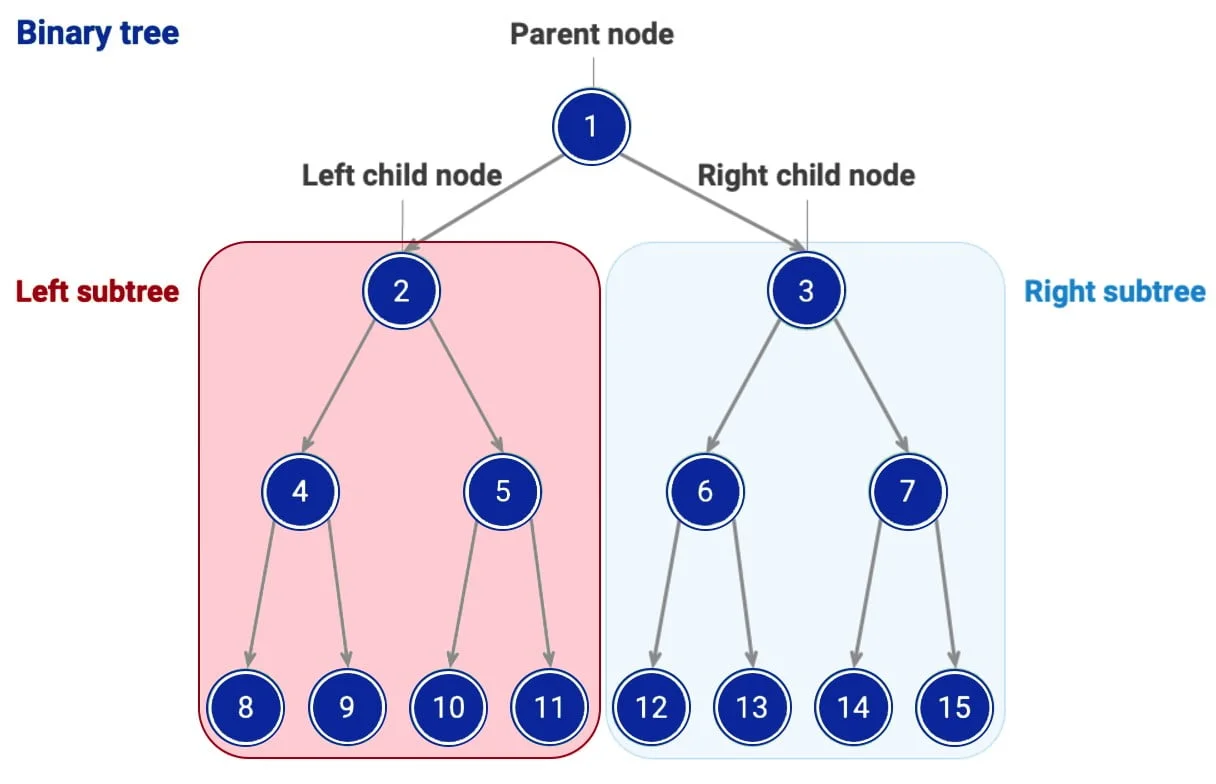
Hierarchische Struktur: Bäume sind in hierarchischen Ebenen angeordnet, wobei die Wurzel an der Spitze steht und die Knoten darunter die nächsten Ebenen darstellen.
Knoten und Kanten: Jeder Knoten enthält Daten und Links zu seinen Unterknoten. Kanten stellen Verbindungen zwischen Knoten dar.
Wurzel: Dies ist der oberste Knoten eines Baums, der keinen übergeordneten Knoten hat.
Blätter: sind Knoten, die keine Nachfolger haben (auch als Endknoten bekannt).
Höhe des Baums: Die Anzahl der Kanten auf dem längsten Pfad von der Wurzel zum Blatt.
Binärer Baum: jeder Knoten kann höchstens zwei Nachkommen haben – einen linken und einen rechten Knoten.
Binärer Suchbaum (BST): ein binärer Baum, bei dem die linken Teilbäume Werte enthalten, die kleiner als ein Knoten sind, und die rechten Teilbäume Werte enthalten, die größer als ein Knoten sind.
Ausgeglichene Bäume: Bäume, wie z.B. AVL oder rot-schwarze Bäume, die eine ausgewogene Höhe für einen effizienteren Betrieb haben.
N-ärer Baum: Knoten können bis zu N Kindknoten haben.
Trie: Spezialisierter Baum für die effiziente Suche, zum Beispiel bei der Arbeit mit Wörtern oder Präfixen.
Stellen wir uns einen Stammbaum vor – die Wurzel des Baumes steht für den ältesten Vorfahren und die Knoten darunter für dessen Nachkommen. Diese Hierarchie ist ein direktes Beispiel für die Verwendung eines Baums zur Organisation und klaren Darstellung von Daten.
Bäume sind eine der wichtigsten Datenstrukturen in der Computerwissenschaft. Ihre Fähigkeit, komplexe Beziehungen zu modellieren und hierarchische Daten effizient zu bearbeiten, macht sie zu einem integralen Bestandteil moderner Algorithmen und Anwendungen.
Ein Graph ist eine nichtlineare Datenstruktur, die Objekte (Knoten, auch als Vertices bezeichnet) und die Beziehungen zwischen ihnen (genannt Kanten) darstellt. Diese Struktur ist äußerst vielseitig und wird verwendet, um verschiedene Situationen zu modellieren, wie soziale Netzwerke, Verkehrskarten oder Beziehungen zwischen Entitäten in Datenbanken.
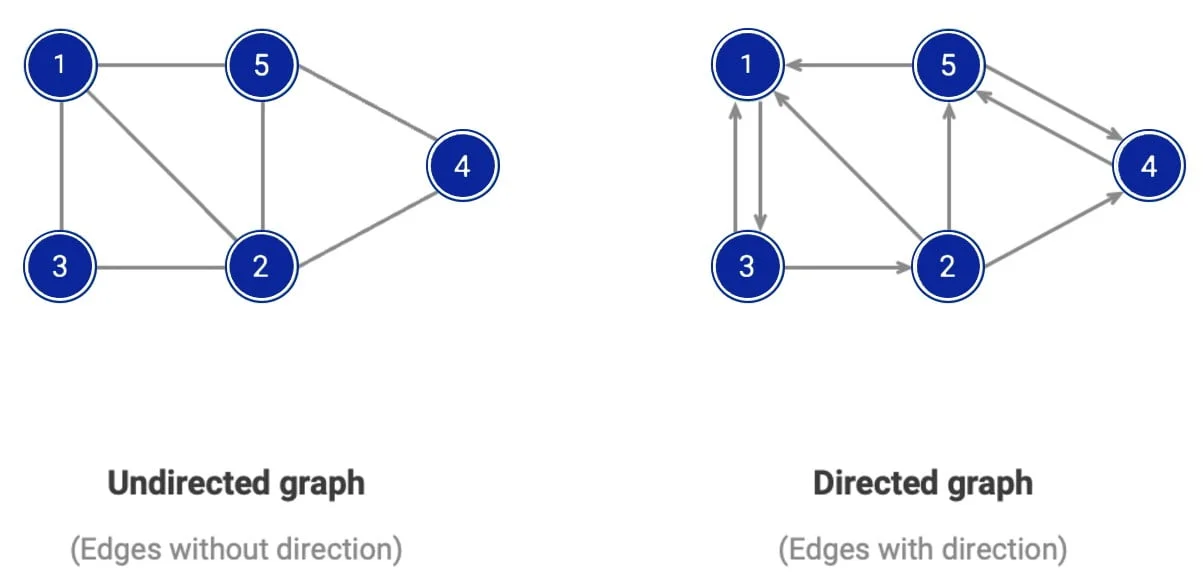
Knoten (Nodes): die grundlegenden Teile des Graphen, die Objekte oder Entitäten darstellen.
Kanten (Edges): Verbindungen zwischen Knoten, die Beziehungen oder Interaktionen darstellen.
Orientierung: Der Graph kann orientiert sein (gerichtete Kanten, z. B. eine Einbahnstraße) oder nicht orientiert (keine Richtung, z. B. eine Straße mit zwei Richtungen).
Kantengewichtung: Einige Diagramme enthalten Gewichtungen an den Kanten, um Werte wie Entfernungen, Kosten oder Zeit darzustellen.
Ungerichteter Graph (Undirected Graph): Kanten haben keine Richtung, die Verbindung zwischen zwei Knoten ist gegenseitig.
Gerichteter Graph (Directed Graph oder Digraph): Kanten haben eine Richtung und verbinden Knoten in einer bestimmten Reihenfolge.
Gewichteter Graph (Weighted Graph): den Kanten wird ein Wert (Gewicht) zugewiesen.
Zyklischer Graph (Cyclic Graph): enthält geschlossene Pfade (Zyklen).
Azyklischer Graph (Acyclic Graph): enthält keine Zyklen.
Baum (Tree Graph oder Tree): ein Spezialfall eines azyklischen Graphen, bei dem jeder Knoten über einen einzigen Pfad zugänglich ist.
Zusammenhängender Graph (Connected Graph): es gibt einen Pfad zwischen zwei Knotenpunkten.
Stellen wir uns ein städtisches Verkehrsnetz vor. Jeder Ort (Haltestelle) ist ein Knoten und die Verbindung zwischen Haltestellen ist eine Kante. Um den schnellsten Weg zwischen zwei Orten zu finden, verwenden wir einen Algorithmus, der den Graphen durchläuft und die kürzeste Route ermittelt.
Graphen sind unverzichtbar bei der Lösung komplexer Probleme, bei denen es darauf ankommt, die Beziehungen zwischen Objekten zu verstehen und analysieren zu können. Dank ihrer Vielseitigkeit und der reichhaltigen Möglichkeiten ihrer Anwendung sind sie zur Grundlage vieler Bereiche der modernen Computerwissenschaft geworden.
Jetzt werden wir die tabellarischen Datenstrukturen, ihre grundlegenden Eigenschaften, Typen, Vor- und Nachteile sowie die häufigsten Anwendungsfälle/Beispiele im Detail besprechen.
Eine Hashtabelle ist eine Datenstruktur, die ein assoziatives Array implementiert, in dem Werte (Daten) anhand eines eindeutigen Schlüssels gespeichert und abgerufen werden. Sie verwendet eine Hash-Funktion, die den Schlüssel in einen Index im Array umwandelt und so eine effiziente Speicherung und den Zugriff auf die Daten ermöglicht.
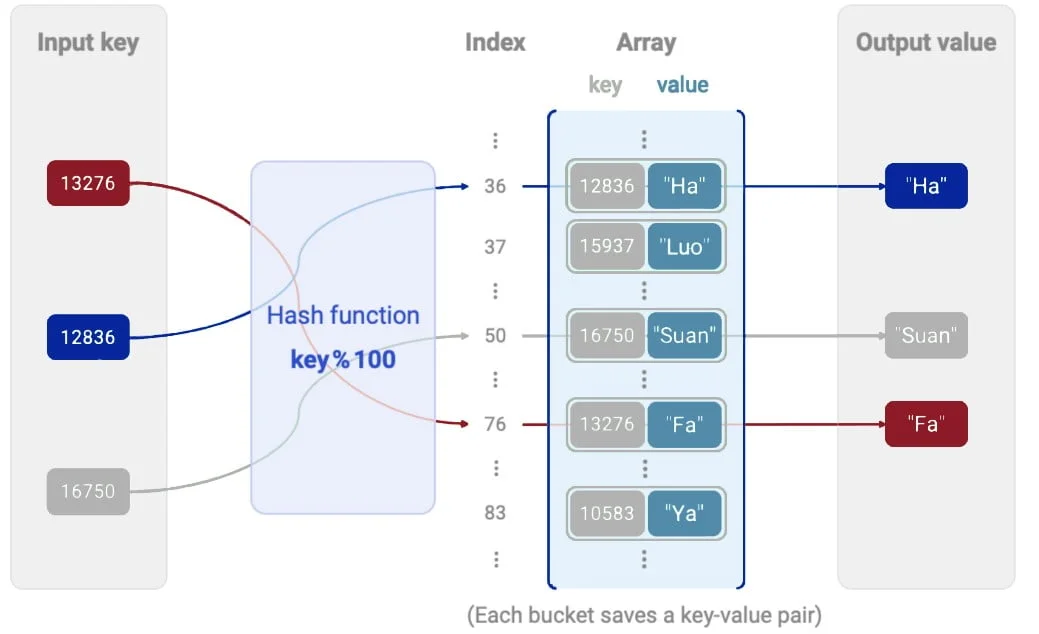
Hash-Funktion: Der Schlüssel wird mithilfe dieser Funktion in einen Index im entsprechenden Feld umgewandelt. Die Qualität der Hash-Funktion bestimmt die Leistung der Tabelle.
Eindeutige Schlüssel: jedem Datensatz in der Tabelle wird ein eindeutiger Schlüssel zugewiesen.
Kollisionen: Wenn zwei verschiedene Schlüssel denselben Index erzeugen, kommt es zu einer Kollision, die durch spezielle Techniken (z.B. Separates Verketteln) aufgelöst wird.
Separates Verketteln: Jeder Index in der Tabelle enthält eine Liste oder eine andere Struktur, die alle Werte mit demselben Index speichert.
Offene Adressierung: Wenn eine Kollision auftritt, wird ein anderer freier Speicherplatz nach einem bestimmten Muster gesucht (z.B. lineares oder quadratisches Sondieren).
Stellen wir uns ein Telefonbuch vor, in dem wir schnell die Nummer einer Person anhand ihres Namens nachschlagen möchten. Der Name der Person dient als Schlüssel, der mithilfe der Hash-Funktion in einen Index umgewandelt wird. Die entsprechende Telefonnummer wird in diesem Index gespeichert.
Hash-Tabellen sind eine leistungsstarke und effiziente Struktur für eine Vielzahl von Anwendungen, bei denen der schnelle Zugriff auf Daten eine Priorität ist. Ihre Fähigkeit, große Datenmengen effizient zu verarbeiten, macht sie im gesamten IT-Bereich unverzichtbar.
Ich möchte noch kurz einige der weniger bekannten Datenstrukturen erwähnen, die uns in der IT begegnen können.
Ein binärer Baum, der die folgende Bedingung erfüllt (jeder Elternknoten ist größer oder kleiner als seine Kindknoten). Er wird zur Implementierung von Prioritätswarteschlangen oder in einem Heap-Sort-Algorithmus verwendet, den wir bereits in unserem Blog vorgestellt haben.
Ein Trie ist eine für die Suche nach Zeichenketten optimierte Baumtabellenstruktur, bei der jeder Knoten einen Teil eines Schlüssels darstellt. Sie wird in Textverarbeitungsprogrammen, bei der automatischen Vervollständigung oder bei der Suche in Datenbanken verwendet.
Es wird verwendet, um Mengen mit disjunkten Elementen darzustellen und zu verwalten. Er wird in Graph-Algorithmen wie dem Kruskal-Algorithmus verwendet.
Ein Baum, der entwickelt wurde, um Probleme im Zusammenhang mit Intervallen und Datenbereichen effizient zu lösen. Er eignet sich für schnelle Operationen zur Bestimmung der Summe, des Minimums oder des Maximums eines Bereichs.
Effiziente Struktur zum Aktualisieren und Suchen von Summen in Sequenzen. Sie wird in Aufgaben verwendet, die Bereiche berechnen.
Ein spezialisierter Baum zum Organisieren von Punkten im K-dimensionalen Raum. Er wird in Algorithmen für Bildverarbeitung, Computer Vision und Datenbanksuche verwendet.
Stellt alle Suffixe einer gegebenen Zeichenkette dar. Es ist besonders effektiv bei der Teilstringsuche und textbasierten Algorithmen.
Matrixtabellen sind zwei- oder mehrdimensionale Arrays, die Daten in Zeilen und Spalten speichern. Sie werden z.B. in der linearen Algebra für die Arbeit mit Matrizen verwendet.
Eine zweidimensionale Matrix, bei der die Zeilen und Spalten die Knoten des Graphen darstellen und die Werte in der Matrix die Existenz von Kanten zwischen den Knoten anzeigen. Sie wird verwendet, um dichte Graphen effizient darzustellen und das Vorhandensein einer Kante zwischen zwei Scheitelpunkten schnell zu erkennen.
Eine Liste, in der jeder Knoten des Graphen eine Liste aller benachbarten Knoten enthält. Ideal für die Darstellung spärlicher Graphen, da sie im Vergleich zu einer Adjazenzmatrix Speicherplatz spart.
Struktur zum Speichern von Matrizen mit den meisten Nullwerten, wobei nur Nicht-Nullwerte und ihre Positionen gespeichert werden. Sie wird in Bereichen wie maschinelles Lernen, Graphenanalyse und Modellierung großer spärlicher Datenstrukturen verwendet.
Eine hashtabellenähnliche Struktur, die Kollisionen auf eine alternative Weise der Schlüsselverteilung auflöst. Effizient bei der Verarbeitung großer Datenmengen mit geringerem Risiko von Clusterkollisionen in Hash-Strukturen.
Datenstrukturen sind ein wesentlicher Bestandteil der Programmierung, da sie eine Möglichkeit bieten, Daten effizient zu organisieren, zu verarbeiten und zu manipulieren. Lineare Datenstrukturen (Warteschlange, Stapel, verkettete Liste, Array) haben spezifische Vor- und Nachteile und Anwendungsbereiche.
Ihre richtige Auswahl und Implementierung kann die Leistung und Effizienz der Software erheblich beeinflussen. Daher ist das Verständnis der grundlegenden Prinzipien von Datenstrukturen für jeden, der sich tiefer mit Programmierung, Algorithmen oder Datenbanken befassen möchte, von entscheidender Bedeutung, damit er dieses Wissen nutzen kann, um optimierte und innovative Lösungen zu entwickeln.
Wenn du auf der Suche nach einem Job bist und ein Java-Programmierer bist, schau dir unsere Mitarbeiter-Benefits an und bewirb dich auf unsere aktuellen Stellenangebote.

Ähnliche Artikel
